透過網路來存取使用了WebAssembly程式的網頁時,愈小的WebAssembly程式會讓網頁的載入速度更快,也會讓使用者體驗更好。這篇文章整理了一些造成WebAssembly程式肥大的原因,以及能使WebAssembly程式縮小的方式。
查看WebAssembly程式的大小
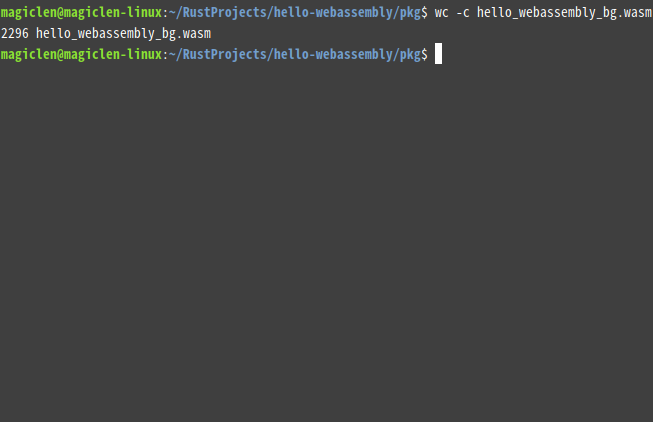
查看WebAssembly程式大小的最簡單方式,當然就是直接去看.wasm檔案的大小啦!在Linux作業系統下,可以用以下指令來查看某個檔案的大小。
wc指令可以用來計算檔案內容的行數、字數、大小等等。-c參數表示要讓wc計算檔案大小。
只不過光看.wasm檔案的大小並無法分析出WebAssembly程式肥大的原因,所以最好還是搭配其它的工具來查看大小比較好。twiggy是一個用Rust程式語言開發的指令工具,可以用來分析.wasm檔案的大小。可以直接執行以下指令來安裝:
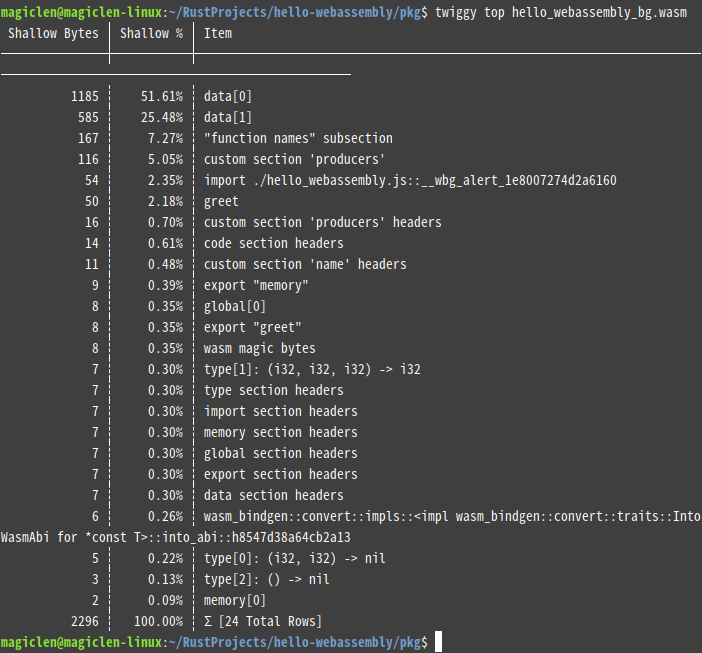
若要找出WebAssembly程式中,各個函數的大小,可以執行以下指令:
twiggy就會由大到小,把WebAssembly程式中的函數輸出。
如果覺得輸出的函數太多了,會看到眼花撩亂的話,可以在指令中加上-n參數,再接上一個數值,來設定最多要輸出幾個函數。例如要限制只輸出前10大的函數,指令如下:
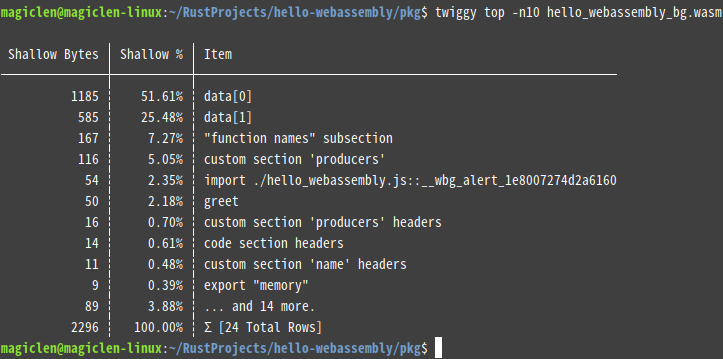
在這邊有兩個名詞需要解釋一下,一個是「Shallow Size」,一個是「Retained Size」。前者是單一函數本身的大小,後者是函數本身的大小再加上其所直接或間接呼叫到的其它函數的大小。twiggy預設是顯示「Shallow Size」,如果要改顯示「Retained Size」的話,可以加上--retained參數。
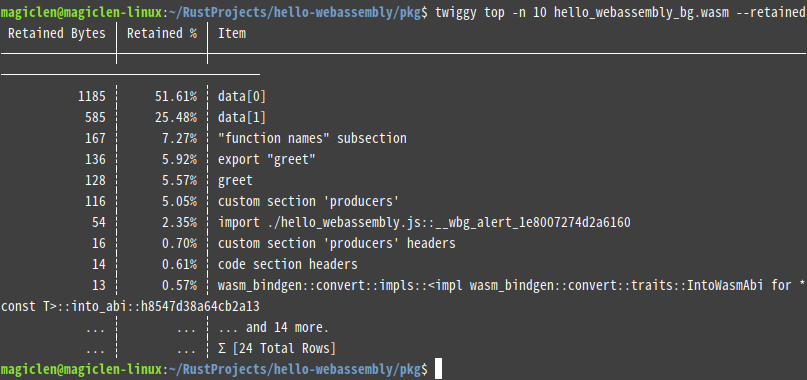
如果我們正在優化WebAssembly程式的大小,也可以利用twiggy來判斷兩個(修改前和修改後的).wasm檔案的大小差異。指令如下:
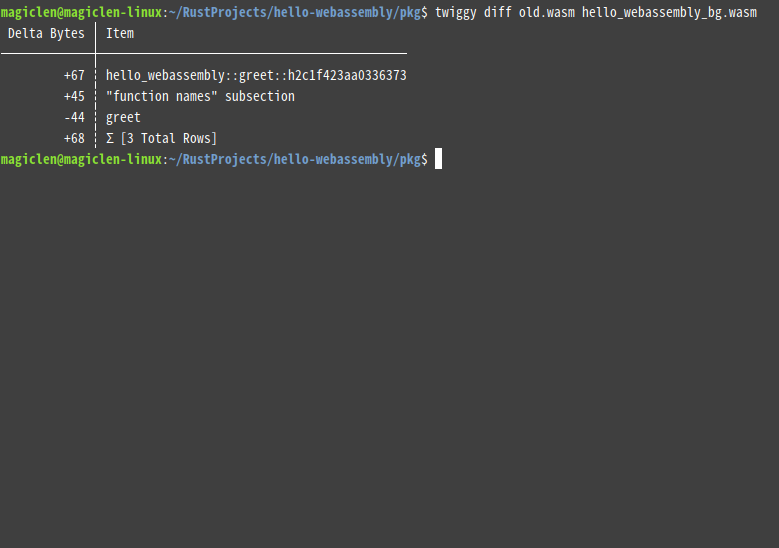
這種指令預設只會顯示差異最大的前20個函數,如果要修改這個限制值的話,可以在指令中加上-n參數,再接上一個數值。例如要限制只輸出前10大的函數,指令如下:
會讓WebAssembly程式的大小顯著增加的程式碼
有些程式碼,可能只寫了一行就會讓WebAssembly程式大小劇烈增加。底下會以第一章的Hello World程式為基準,來說明加了哪些特定程式碼後,會讓WebAssembly程式變肥。
我們的Hello World程式的.wasm檔案的大小為2296個位元組。
format!等用來格式化字串的巨集
format!、println!等巨集最好不要用在WebAssembly程式中,如果我們試著將Hello World程式修改為:
...
#[wasm_bindgen]
extern {
fn alert(s: &str);
}
#[wasm_bindgen]
pub fn greet() {
greet_inner("world");
}
fn greet_inner(target: &str) {
alert(format!("Hello, {target}").as_str());
}
...
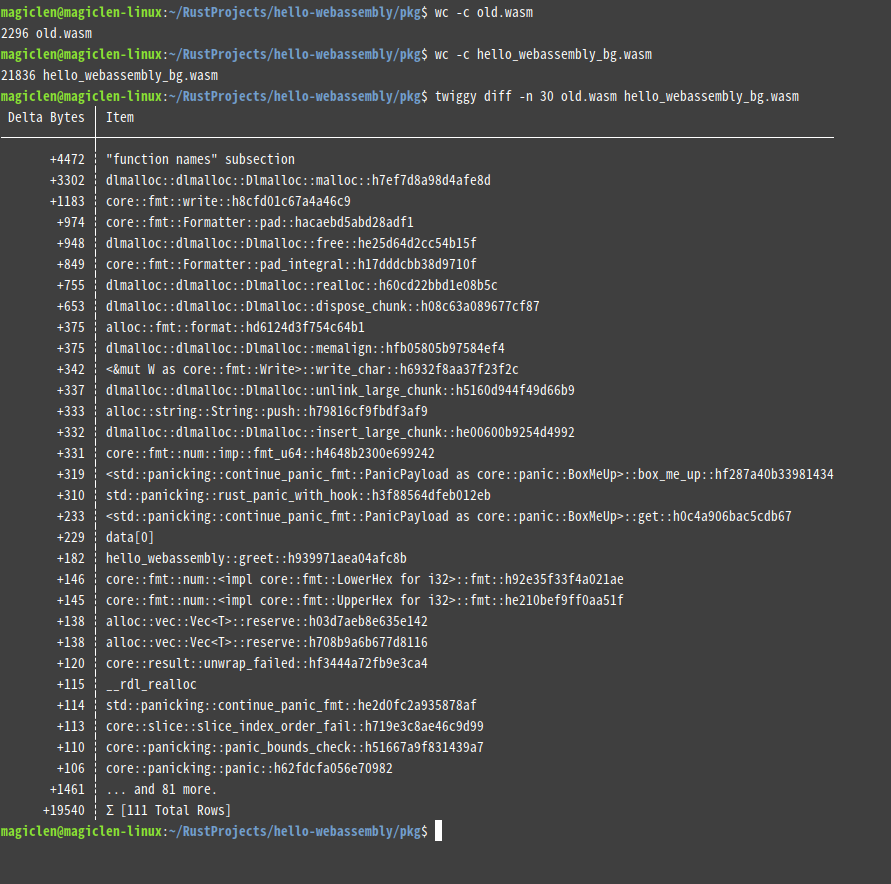
以上程式,編譯出來的.wasm檔案的大小為21836個位元組,幾乎是原先的10倍!
為什麼會這樣呢?透過twiggy diff指令來分析兩個.wasm檔案的差異,可以發現WebAssembly程式中多了很多panic和dlmalloc相關的東西。dlmalloc是Rust程式語言預設的分配器。
既然如此,您可能會想問:那麼改用wee_alloc的話,會如何呢?
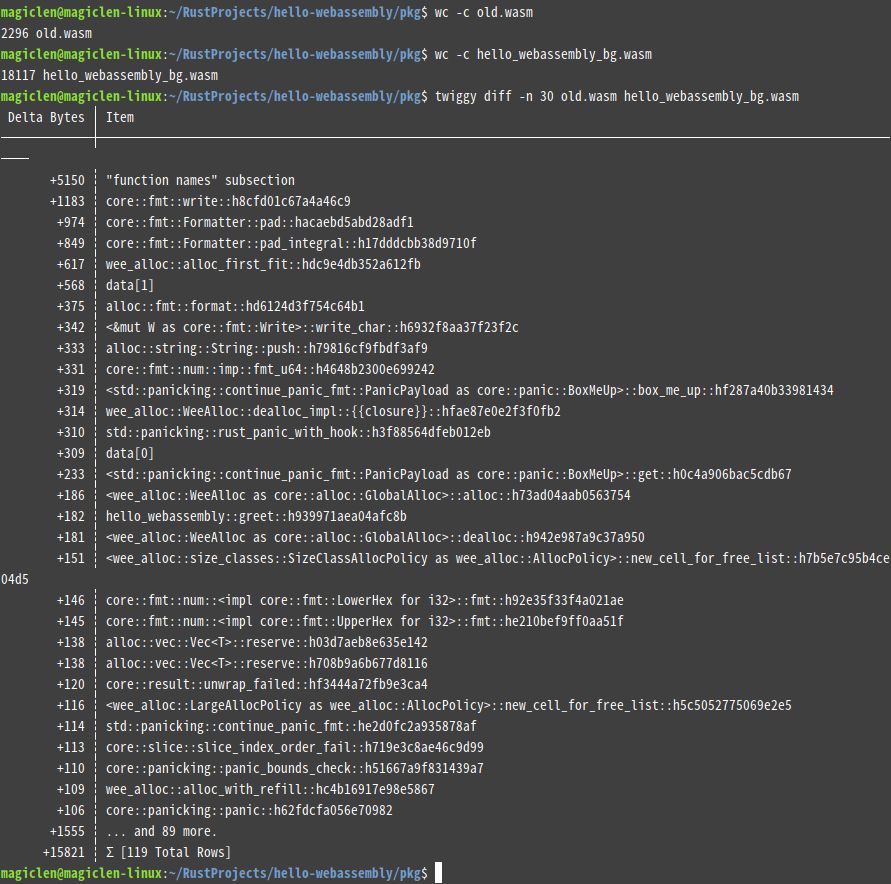
改用wee_alloc的話,編譯出來的.wasm檔案的大小為18117個位元組,雖然小了一些,但還是太大了!
因此,我們應該要避免使用格式化字串的巨集來處理字串。那如果我們將這個程式優化成如下的樣子呢?
...
#[wasm_bindgen]
extern {
fn alert(s: &str);
}
#[wasm_bindgen]
pub fn greet() {
greet_inner("world");
}
fn greet_inner(target: &str) {
let mut s = String::from("Hello, ");
s.push_str(target);
alert(s.as_str());
}
...
dlmalloc編譯出來的大小為21053個位元組;wee_alloc編譯出來的大小為17503個位元組。是會比直接用format!巨集還要小沒錯,但並沒有很明顯。
那該怎麼做才不會讓WebAssembly程式一下子增大那麼多呢?其實這個沒有什麼好方法能解決,只要有在程式中做到配置(allocate)記憶體的動作,分配器的程式碼就會被大量編譯進WebAssembly程式中,這個只能說是WebAssembly程式的基本開銷。
不過我們也不用過度擔心,字串處理的基本門檻過了之後,WebAssembly程式的大小就不會增加那麼快了。例如以下程式:
...
#[wasm_bindgen]
extern {
fn alert(s: &str);
}
#[wasm_bindgen]
pub fn greet() {
greet_inner("world");
}
fn greet_inner(target: &str) {
let mut s = String::from("Hello, ");
s.push_str(target);
alert(s.as_str());
let mut s = String::from("Hi, ");
s.push_str(target);
alert(s.as_str());
let mut s = String::from("Magic ");
s.push_str(target);
alert(s.as_str());
}
...
以上程式,dlmalloc編譯出來的大小為21250個位元組;wee_alloc編譯出來的大小為17390個位元組。雖然多了兩倍的字串處理量,但程式大小並沒有增長太多。
但是,如果是重複使用格式化字串的巨集來處理字串的話,程式大小的增長會更明顯一些。
...
#[wasm_bindgen]
extern {
fn alert(s: &str);
}
#[wasm_bindgen]
pub fn greet() {
greet_inner("world");
}
fn greet_inner(target: &str) {
alert(format!("Hello, {target}!").as_str());
alert(format!("Hi, {target}!").as_str());
alert(format!("Magic {target}!").as_str());
}
...
以上程式,dlmalloc編譯出來的大小為22192個位元組;wee_alloc編譯出來的大小為18457個位元組。
所以如果一定要做字串處理的話,最好還是避免使用格式化字串的巨集啦!如果為了偵錯(Debug)方便,還是要用的話,就限定在非Release的模式下用吧!
panic
會讓程式發生panic的程式碼也儘量不要撰寫。其實在上一個小節介紹字串時,我們就可以在twiggy diff指令的輸出結果中,看到名列前茅的項目有很多是跟panic有關的。
如果我們試著將Hello World程式修改為:
...
#[wasm_bindgen]
extern {
fn alert(s: &str);
}
#[wasm_bindgen]
pub fn greet() {
panic!();
}
...
以上程式,dlmalloc編譯出來的大小為18295個位元組;wee_alloc編譯出來的大小為14560個位元組。
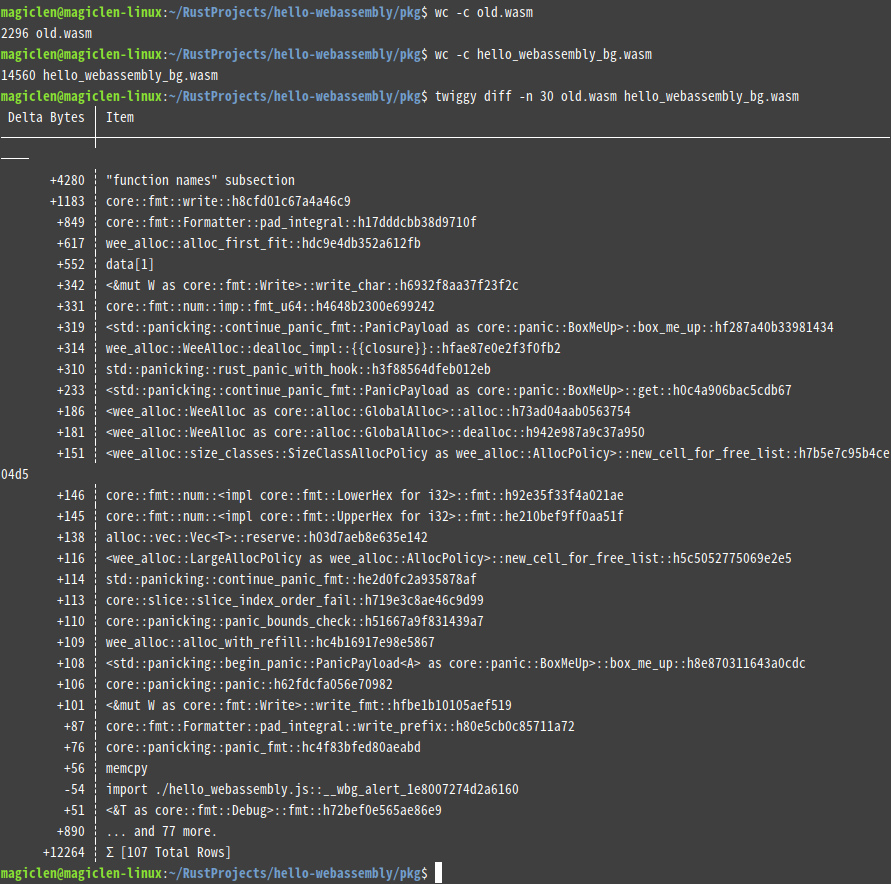
當然,若使用到Option或是Result列舉的unwrap相關方法,背後也是一樣會去用到panic!巨集。如果我們真的不想要在WebAssembly程式中加上panic相關的程式碼,就把有用到unwrap相關方法的地方,都改用如下的函數:
#[inline]
fn option_unwrap_abort<T>(o: Option<T>) -> T {
use std::process;
match o {
Some(t) => t,
None => process::abort(),
}
}
#[inline]
fn result_unwrap_abort<T>(r: Result<T>) -> T {
use std::process;
match r {
Ok(t) => t,
Err(_) => process::abort(),
}
}
不過也並不是只有呼叫到panic!巨集才會有panic程式。取得陣列元素或是切片的時候,也是有機會讓程式發生panic,甚至做整數除法運算的時候也會有(除以0)!
要完全擺脫panic程式並不是一件容易的事情,這個也可以說是WebAssembly程式的基本開銷。
泛型
在本站的《Rust學習之路》系列文章中的物件導向章節,有提到泛型其實是在做「靜態調度」(Static dispatch),編譯器在編譯程式時會自動把有泛型定義的項目解開。所以一個泛型的項目,實際上可能會有很多個不同的版本,這個就會導致.wasm檔案的大小增加啦!
所以為了讓相同的結構體、函數等項目能夠被重複使用,進而減少WebAssembly程式的大小,可以改用「動態調度」(Dynamic dispatch)的方式來傳遞資料。
可能可以讓WebAssembly程式變小的方法
啟用LTO(Link Time Optimization)並修改編譯器優化等級
參考這篇文章來了解LTO和編譯器優化等級:
可以試著啟用LTO並將編譯器優化等級設為s或是z來縮小編譯出來的WebAssembly程式。
WebAssembly Binary Toolkit(WABT)的wasm-strip
如果您有注意去看twiggy top指令的輸出結果,那麼應該會發現「"function names" subsection」總是名列前茅,而且榜單上可能還會夾雜著幾個「custom section "xxxx"」。這些到底是什麼東東?
「Custom Section」是.wasm檔案的某段內容,用來存放偵錯時能提供給人類閱讀的資訊,像是模組名稱、函數名稱、變數名稱等等。就如同原生(native)程式可以用strip指令工具來去除掉這些偵錯資訊一樣,WebAssembly也有類似的工具能用。
WebAssembly Binary Toolkit是用C++開發的開源工具包,其提供的wasm-strip指令工具可以用來移除.wasm檔案中的「Custom Section」。
可以利用以下連結開啟WABT的GitHub的Release頁面,下載官方已經替不同平台編譯好的執行檔,其中就包含wasm-strip的執行檔。
若要使用wasm-strip來將.wasm檔案瘦身,指令的用法如下:
wasm-strip /path/to/webassembly-file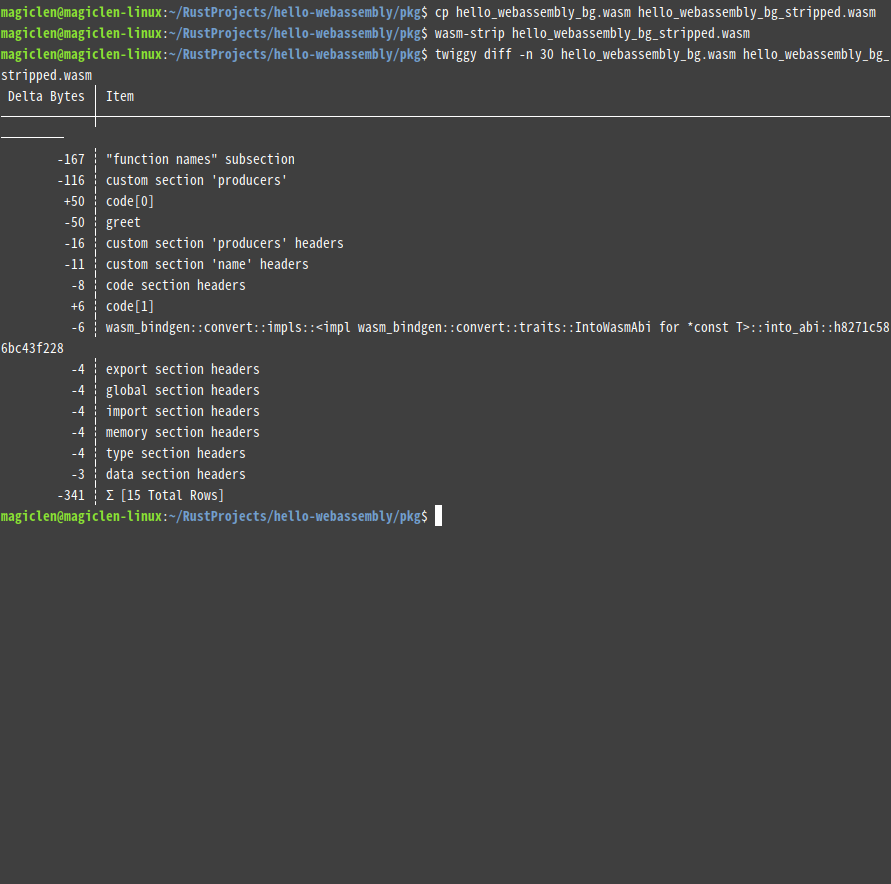
Binaryen的wasm-opt指令工具
Binaryen是用C++開發的開源WebAssembly工具包,其提供的wasm-opt指令工具可以用來優化.wasm檔案。
可以利用以下連結開啟Binaryen的GitHub的Release頁面,下載官方已經替不同平台編譯好的執行檔,其中就包含wasm-opt的執行檔。
若要使用wasm-opt來優化.wasm檔案,指令的用法如下:
-O參數表示要對.wasm檔案做優化,其後可以再接上一個字元來決定優化的等級。0表示不優化;1~4數字愈高表示要啟用愈多的優化方式;s表示要針對檔案大小作優化;z表示要比s還更針對檔案大小作優化。預設值為s。
如果我們twiggy diff一下優化前後的差異,會發現wasm-opt其實也有去刪除「Custom Section」。
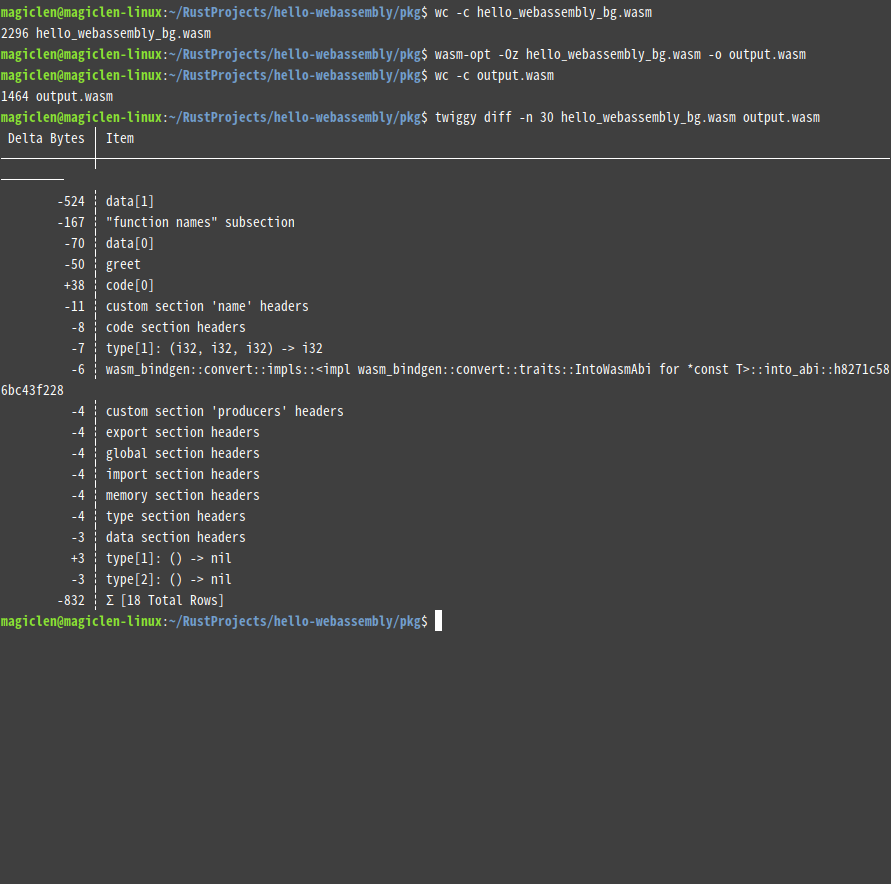
所以用wasm-opt就不需要用wasm-strip了嗎?其實也並非如此,如果再注意看的話,會發現wasm-opt和wasm-strip清出來的「Custom Section」相關項目還是有些小差異。
筆者是建議先用wasm-strip後再用wasm-opt,因為wasm-opt不一定能成功……
總結
雖然這整個章節都在講WebAssembly程式的大小,但筆者還是覺得它仍然是個大問題。即便有能夠優化WebAssembly程式的外部工具,但不見得能適用在所有的WebAssembly程式上,這是蠻可惜的地方。不過還是希望以後用Rust程式語言開發WebAssembly程式可以不需要借助外部工具就能夠把程式優化到好,不然實在是有點麻煩呀!
這個系列的文章就到這裡為止了,姑且不論WebAssembly程式的大小,用Rust程式語言開發WebAssembly程式算是非常方便的,而且也容易維護。早期筆者有玩過一點點的asm.js,它算是WebAssembly的前身,那個時候還不知道它可以用來做什麼,就只是把自己以前寫的C語言程式用Emscripten轉一轉後在網頁瀏覽器上執行,然後覺得新奇、很酷。完全沒想到發展到現在,WebAssembly可以做到這麼多事,而且還能夠用很多種高階程式語言來寫呢!