在建置Cargo程式專案的時候,我們可以輕易地使用cargo build或是cargo build --release指令,來對開發(development)或是發佈/部署(deployment)的目的做區分。cargo build編譯出來的二進制檔案沒有經過最佳化,而且會啟用#[cfg(debug_assertions)]屬性,來使用偵錯(debug)相關的程式碼;cargo build --release則允許使用編譯器所有的最佳化功能,並禁用有加上#[cfg(debug_assertions)]屬性的程式碼。不過cargo build --release實際上並不一定會去啟用所有的最佳化功能,有些最佳化項目還是需要靠其它編譯器參數來啟用才行。這些編譯優化參數,究竟有什麼實質影響呢?這篇文章將會對效能、檔案大小和編譯時間進行探討。
為了方邊進行我們的編譯優化研究,先來製作一個簡單的Cargo程式專案吧!
首先用以下指令來建立一個名為crc64sum的Cargo應用程式專案:
專案內容如下:
[package]
name = "crc64sum"
version = "0.1.0"
edition = "2021"
[dependencies]
crc-any = "2"
use std::{
error::Error,
fs::File,
io::{self, Read},
};
use crc_any::CRCu64;
pub struct Config {
filepath: String,
}
impl Config {
pub fn new(filepath: String) -> Config {
Config {
filepath,
}
}
}
pub fn compute_file_crc(mut file: File) -> Result<u64, io::Error> {
let mut crc64_ecma = CRCu64::crc64();
let mut buffer = [0u8; 256];
loop {
let c = file.read(&mut buffer)?;
if c == 0 {
break;
}
crc64_ecma.digest(&buffer[..c]);
}
Ok(crc64_ecma.get_crc())
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let file = open_file(&config.filepath)?;
let crc_value = compute_file_crc(file)?;
println!("{crc_value:x}");
Ok(())
}
fn open_file(filepath: &str) -> Result<File, io::Error> {
File::open(filepath)
}
use std::{env, error::Error};
use crc64sum::*;
fn main() -> Result<(), Box<dyn Error>> {
let config = Config::new(env::args().nth(1).ok_or("not enough arguments")?);
crc64sum::run(config)?;
Ok(())
}
crc64sum是一個指令工具,可以利用CRC64-ECMA演算法去計算某個檔案的校驗碼(checksum)。
Debug與Release
筆者習慣將用cargo build指令編譯程式的方式稱為「Debug編譯模式」;用cargo build --release指令編譯程式的方式稱為「Release編譯模式」。
如下圖,若直接使用Debug編譯模式來建置crc64sum專案,所花的時間為0.533秒,最終產生3180 KB的執行檔。
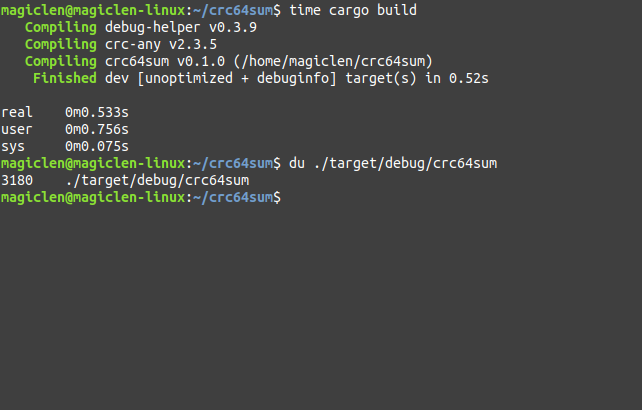
如下圖,若使用Release編譯模式來建置crc64sum專案,所花的時間為0.548秒,最終產生2808 KB的執行檔。
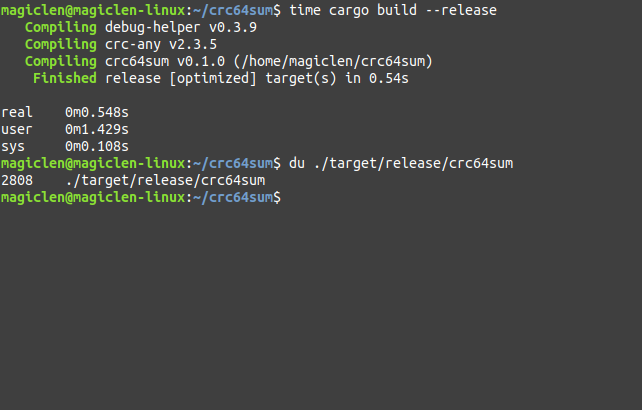
可以發現,Release編譯模式所花費的編譯時間要比Debug編譯模式還要來得長(具體長多久並不一定,程式專案規模愈大,會讓Release編譯模式所需的時間比Debug編譯模式還要長愈多倍),產生出來的執行檔也會比較小。
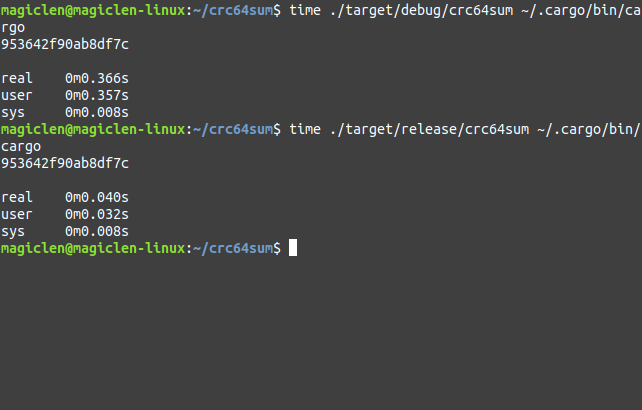
接著來比較這兩個執行檔的效能。例如去計算cargo執行檔的CRC校驗碼,Debug模式編譯出來的執行檔需要0.366秒;Release模式編譯出來的執行檔只需要0.040秒。結果如下圖:
opt-level
在Cargo.toml的[profile.dev]區塊和[profile.release]區塊可以設定opt-level項目,分別對Debug編譯模式和Release編譯模式設定不同的最佳化等級。
opt-level可以有以下幾種設定值:
0:不進行最佳化,並且啟用#[cfg(debug_assertions)]屬性。1:允許基本最佳化。2:允許常用的最佳化。3:允許所有的最佳化。"s":允許常用的最佳化,外加一些能縮小體積的最佳化。"z":類似"s",但更偏重於體積的最佳化(可能會降低效能)。
Debug編譯模式預設使用0;Release編譯模式預設使用3。
LTO(Link Time Optimization)
LTO顧名思義就是在程式編譯後的連結階段時所採取的最佳化行為,通常可以順帶減少編譯出來的二進制檔案的體積,但也會顯著增加編譯時間和佔用的記憶體,且有時對程式效能並沒有正面的影響,所以Cargo程式專案在建置時預設並沒有啟用LTO。
Rust提供的LTO分為thin和fat兩種,可以被視為兩種不同的LTO實作,彼此編譯出來的程式並沒有絕對的效能優劣(在絕大部份情況下,開啟LTO編譯出來的程式之效能會比沒開啟LTO還要來得好)。但以編譯速度來說,thin似乎總是比fat還要來得快。
在Cargo.toml的[profile.release]區塊可以設定lto項目,在Release編譯模式下啟用LTO。
例如以下設定可以啟用LTO(fat):
[profile.release]
lto = true
此時使用Release模式編譯crc64sum專案需要花1.867秒才能編譯完成,最終產生的執行檔大小只有1128 KB。
例如以下設定可以啟用ThinLTO:
[profile.release]
lto = "thin"
此時使用Release模式編譯crc64sum專案需要花1.466秒才能編譯完成,最終產生的執行檔大小只有1212 KB。
搭配opt-level = "s"或opt-level = "z",還可以再讓編譯出來的檔案變得更小。
Parallel Code Generation Units
在Cargo.toml的[profile.release]區塊可以設定codegen-units項目,來指定編譯器在編譯一個crate的時候要能其切分成多少份來同時處理。預設值是16或256,若改成1,則不進行切分,以增加套用更多的最佳化的機會,提升程式效能,但可能會讓編譯時間上升。
例如以下設定:
[profile.release]
codegen-units = 1
此時使用Release模式編譯crc64sum專案需要花0.746秒,最終產生的執行檔大小為2804 KB。
inline
Rust內建#[inline]屬性,可以手動建議(非強制)編譯器去對某個函數進行內聯(inline)處理,將函數的實作展開(複製)至調用這個函數的地方。內聯的目的在於減少函式呼叫的次數,以避免建立堆疊框(Stack Frame)而有額外的開支(overhead)。對於一個體積極小(例如只有一個表達式)、需要進行快速計算或是為使程式碼易讀而從某個函數中切分出來的函數,我們可以將其加上#[inline]屬性,使它們在編譯的時候可以在被調用的位置上展開。
另外還有#[inline(always)]屬性,可以讓編譯器總是對該函數做內聯,使其更像是類函數(funciton-like)巨集。#[inline(never)]屬性,則可以告訴編譯器不對這個函數做內聯的動作,方便偵錯。
strip
不管是在Debug編譯模式還是Release編譯模式,編譯好的二進制檔都會帶有偵錯資訊。如果我們想讓Rust在Release編譯模式下編譯出來的二進制檔中不帶有不必要的標頭和偵錯資訊,在Cargo.toml的[profile.release]區塊可以將strip項目設為true。
如下:
[profile.release]
strip = true
當編譯出來的執行檔需要公開發佈(publish)時,還可以搭配panic = "abort"一同使用,這部份可以參考這篇文章。
如果只是要個人使用或是在組織內部使用的話,將偵錯資訊和unwinding panic機制保留下來對日後維護會比較方便。此外,如果不想讓執行緒發生panic就讓整個程式直接中斷的話,就不能使用panic = "abort",不過還是可以使用strip = true。