Rust程式語言將錯誤分為「不可恢復的錯誤」(unrecoverable error)和「可恢復的錯誤」(recoverable error),程式開發人員必須依照程式邏輯來自行決定應該要讓程式使用哪種類型的錯誤。
簡單來說,「不可恢復的錯誤」就好比使用超出陣列索引範圍的索引值來存取陣列,但這樣的陣列用法連一次都不應該出現,否則就是程式有Bug(臭蟲)。「可恢復的錯誤」就好比要透過一個檔案路徑來讀取一個檔案,但這個檔案並不存在,因為沒有檔案可讀取,所以就以一個錯誤來代替,當程式判斷到這個錯誤發生的時候,就知道也許要去改用其它的檔案路徑來讀取,或是請使用者再輸入一次正確的檔案路徑。
大部分的程式語言並沒有將錯誤明顯區分為不可恢復或是可恢復,而是直接使用「例外」(exception)機制來統一處理。然而Rust程式語言並沒有例外機制,我們在先前章節遇到的程式panic,就是程式在執行的時候發生了不可恢復的錯誤,所以使用panic來顯示錯誤訊息並中止程式的運行。我們在先前的章節也有學到Result列舉,它就是用來處理可恢復的錯誤。
不可恢復的錯誤用panic!巨集來處理
Rust程式語言提供了panic!這個巨集來印出錯誤訊息,並解開(unwind)目前堆疊中的資料,然後中止程式的運行,換句話說就是能夠讓程式panic。
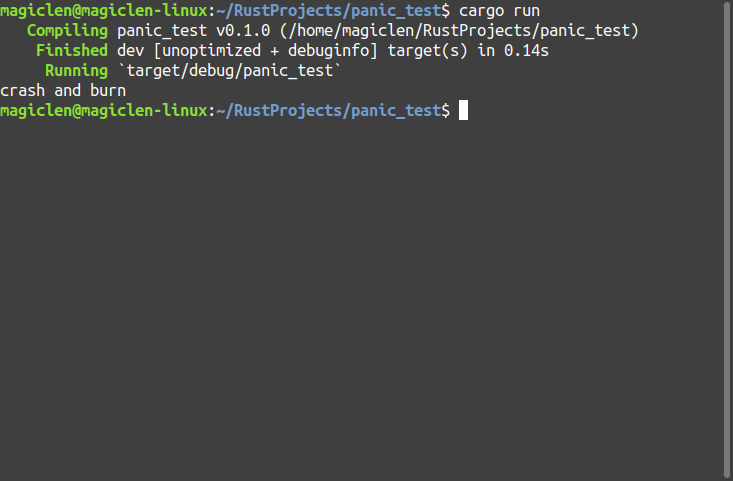
以下程式,在main函數中直接使用panic!巨集來使程式發生panic:
fn main() {
panic!("crash and burn");
}
執行結果如下圖:
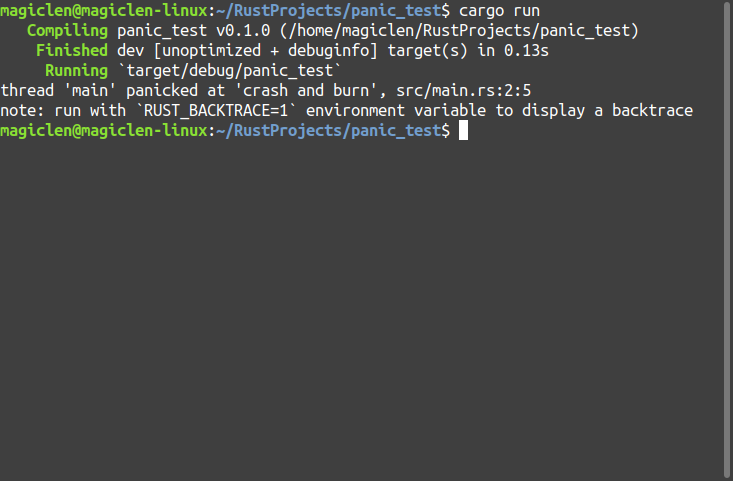
從上圖可以看到,程式執行的錯誤訊息中會有發生panic的執行緒名稱與我們傳進panic!巨集的文字crash and burn,還有產生這個panic的原始碼檔案與行號。此外,也可以看到這個提示note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace,我們也試著加上這個環境變數設定來執行程式吧!執行結果如下圖:
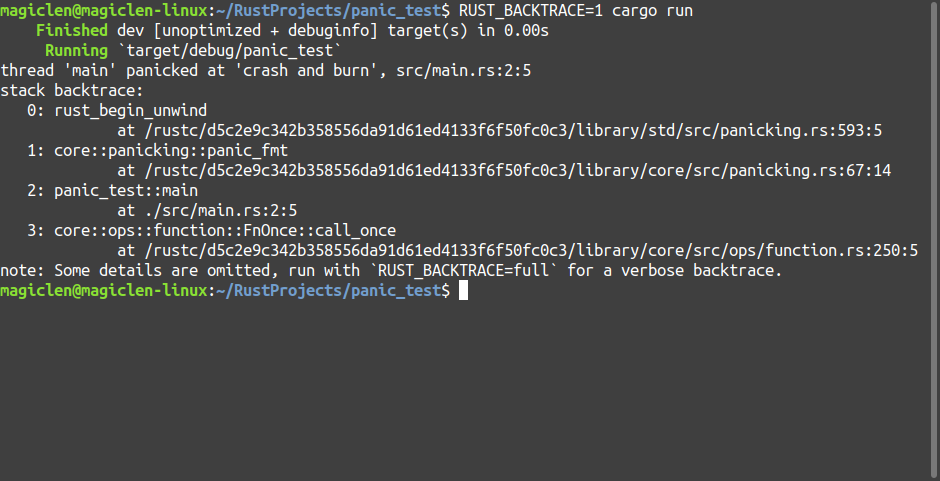
在預設的情況下,當Rust程式發生panic時,會對那個時間點的堆疊資料進行「解開」的動作,如果環境變數RUST_BACKTRACE設為1的話,就會把這些堆疊資料透過標準錯誤(stderr)傳出,使用者就可以知道程式究竟是執行到什麼後才發生這個panic。
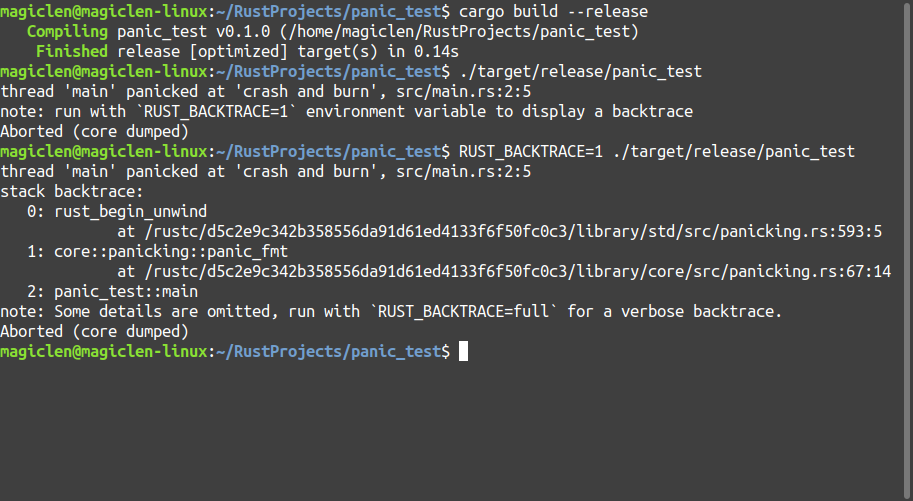
根據執行結果的提示,還可以將環境變數RUST_BACKTRACE設為full,來查看更完整的訊息。執行結果如下圖:
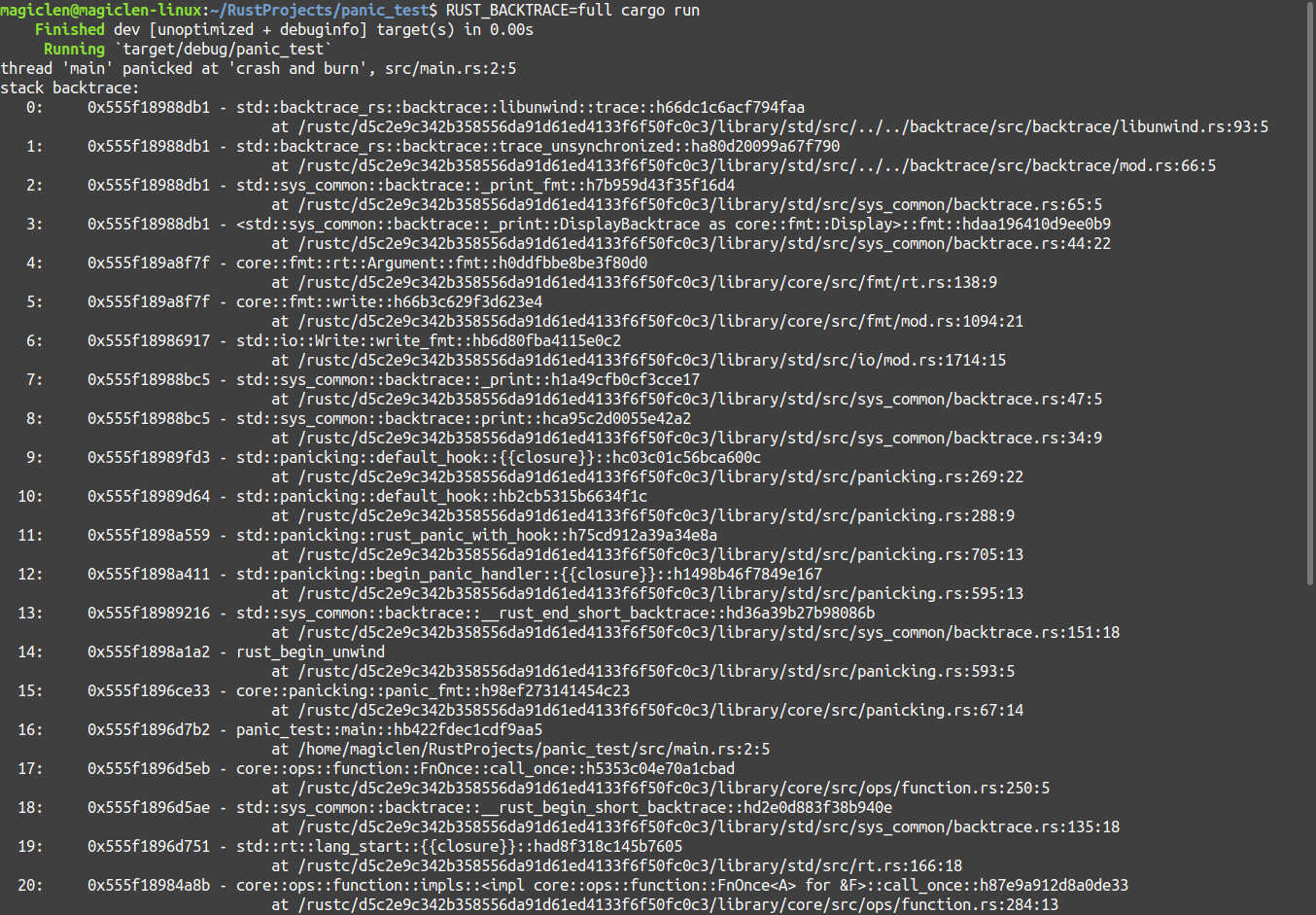
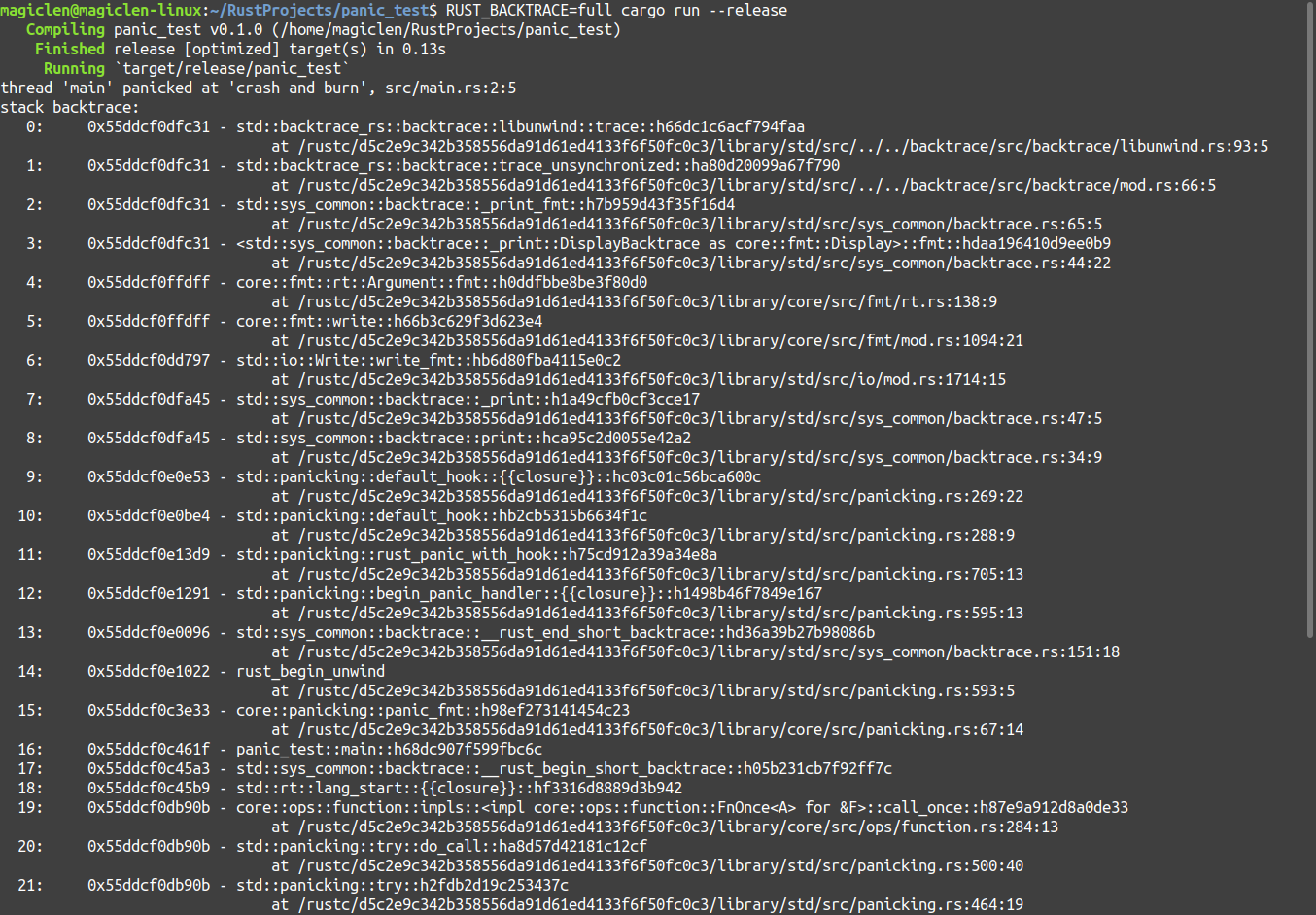
當然,我們也許會擔心製作出來的Rust程式在交付給客戶後會因為程式panic把所有堆疊中有關程式碼的詳細資料都印出來,而使得程式很容易就能被逆向工程反推出原始碼,因為即便使用release模式來編譯程式,也還是會保留這個功能。程式執行結果如下圖:
我們可以在Rust的程式專案的Cargo.toml設定檔中,加入[profile.release]區塊,並將panic設定項目的值設為abort。如下:
[package]
name = "panic_test"
version = "0.1.0"
edition = "2021"
[profile.release]
panic = "abort"
[dependencies]
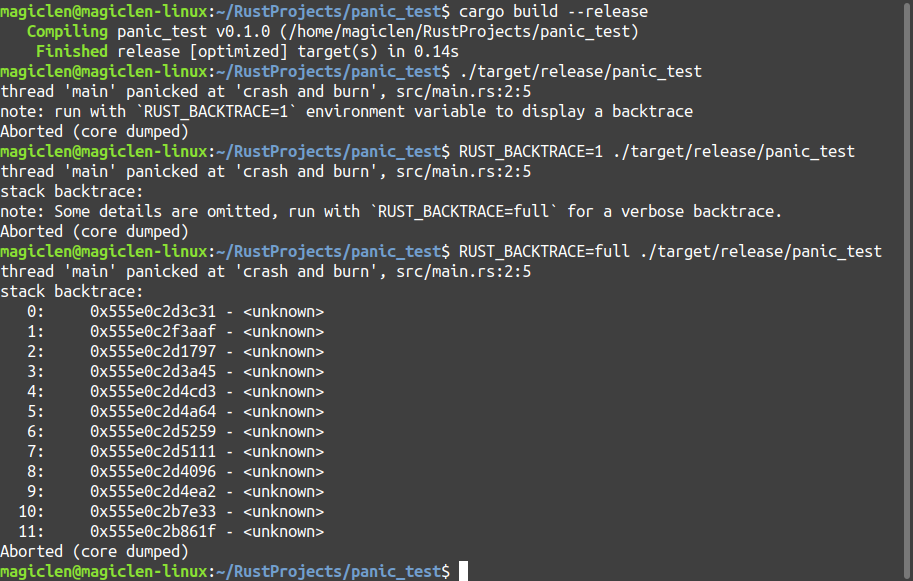
如此一來,之後使用release模式編譯出來的程式發生panic時,就會直接中止程式的執行,而不會去「解開」堆疊空間的資料。但是還是會有一些堆疊資料,在設定環境變數RUST_BACKTRACE之後會被顯示出來。
雖然這些堆疊資料跟我們寫的程式碼無關,顯示出來沒什麼大礙,但如果想要將其消去的話還是有辦法的,那就是在[profile.release]區塊中將strip設定項目的值設為true,將編譯出來的檔案中不必要的標頭和偵錯資訊移除。如下:
[package]
name = "panic_test"
version = "0.1.0"
edition = "2021"
[profile.release]
panic = "abort"
strip = true
[dependencies]
程式執行結果如下圖:
如果要連使用panic!巨集所產生出來的執行緒名稱和產生panic的程式原始碼位置都不要顯示的話,要使用std::panic模組提供的set_hook函數來自訂之後使用panic!巨集時要執行的程式碼。舉例來說:
use std::panic::set_hook;
fn main() {
set_hook(Box::new(|panic_info| {
eprintln!("{}", panic_info.payload().downcast_ref::<&str>().unwrap());
}));
panic!("crash and burn");
}
以上程式,使用panic!巨集後,會去執行第5行程式,利用eprintln!巨集把傳入至panic!巨集的錯誤訊息文字給輸出到標準錯誤(stderr)中。程式第4行到第6行,以我們現在的Rust程式語言功力還看不懂它,也沒關係,現階段如果有需要隱藏panic!巨集所產生出來的執行緒名稱和產生panic的程式原始碼位置的話,就來這裡複製貼上這段程式碼吧!
可恢復的錯誤用Result列舉來處理
先前我們已經探討過列舉的用法了,這裡就不再多說。Rust程式語言的標準函式庫提供的許多函數和方法都會回傳Result列舉的實體,或許我們沒有辦法把這些函數和方法都記下來,但也不用擔心,如果函數或方法有回傳值卻沒有去處理,編譯器會出現警告訊息。原本就應該要回傳資料的函數或方法也會使用Result列舉來包裹,例如std::fs模組中File結構體提供的open函數,其可用來開啟一個指定路徑的檔案。舉例來說:
use std::fs::File;
fn main() {
let f: File = File::open("hello.txt");
}
以上程式,第4行會編譯錯誤,因為open函數回傳的值是Result列舉,而不是直接將File結構實體回傳。可以將程式修改如下:
use std::fs::File;
fn main() {
let f: File = match File::open("hello.txt") {
Ok(file) => file,
Err(error) => {
panic!("There was a problem opening the file: {:?}", error);
}
};
}
以上程式利用match關鍵字來對open函數回傳的值進行型樣匹配,判斷檔案到底有沒有開啟成功。如果有成功,就用宣告出來的f變數儲存File結構實體;如果不成功,就讓程式發生panic。這裡要注意的是,由於使用panic!巨集之後,接下來的程式敘述都執行不到了,因此Err(error)這個arm就算沒有讓它回傳一個File結構實體,程式也不會編譯錯誤。
直接使用Err(error)來做型樣匹配的話,不管是什麼樣的錯誤都會被匹配到。如果我們要將一些特定的錯誤抓出來處理,該怎麼做呢?
舉例來說,我們希望如果發生錯誤的原因是因為檔案不存在,就去建立新檔案出來;而如果是其它錯誤,就讓程式發生panic。程式如下:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(ref error) if error.kind() == ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => {
panic!("Tried to create file but there was a problem: {:?}", e)
},
},
Err(error) => {
panic!("There was a problem opening the file: {:?}", error)
},
};
}
File結構體的open方法所回傳的Result列舉,其Err變體包裹的值為std::io模組下的Error結構體,這個Error結構的實體提供了一個kind方法,可以回傳std::io的ErrorKind列舉的實體,可以用來判斷這個Error結構實體的錯誤類型。以上程式第9行,我們利用「匹配守衛」增加了一個匹配條件,那就是判斷Error結構實體的kind方法回傳的列舉是否為ErrorKind列舉的NotFound變體。File結構體的create方法可以在指定路徑建立檔案,它也會回傳一個Result列舉實體,所以也可以使用match關鍵字來進行型樣匹配。
再來回頭看一下之前的程式:
use std::fs::File;
fn main() {
let f: File = match File::open("hello.txt") {
Ok(file) => file,
Err(error) => {
panic!("There was a problem opening the file: {:?}", error);
}
};
}
雖然Result列舉是用來處理可恢復的錯誤,但我們卻不一定每次都會對它進行特別處理,取而代之的是讓程式再產生不可恢復的錯誤,也就是讓程式發生panic。如果每次遇到不想處理的Result列舉,程式碼都要用以上的方式來撰寫的話,好像就有點過於麻煩。還好Rust程式語言已經替Result列舉實作了不少有用的方法,例如以上這個程式。就可以用unwrap方法來簡化,程式如下:
use std::fs::File;
fn main() {
let f = File::open("hello.txt").unwrap();
}
這個unwrap方法,基本上就是去判斷實體是Ok變體的實體還是Err變體的實體。如果是前者,就直接將Ok實體所包裹的值回傳出來;如果是後者,就會用panic!巨集並代入Err實體包裹的值,來使程式發生panic。
另外,Result列舉還有一個好用的expect方法,這個方法我們在一開始練習寫猜數字程式時就有使用過了。程式如下:
use std::fs::File;
fn main() {
let f = File::open("hello.txt").expect("Failed to open hello.txt");
}
unwrap方法和expect方法的差別在於:unwrap方法是將原本Result列舉所包裹的Err值作為程式panic的錯誤訊息顯示出來;而expect方法則是可以使用我們存參數傳入的字串來作為程式panic的錯誤訊息。
如果我們正在將特定的邏輯功能以函數的方式實作,我們可以考慮把函數中遇到的錯誤以Result列舉來包裹回傳,讓呼叫這個函數的呼叫者(caller)自行去處理函數在執行過程中所遭遇的錯誤。舉例來說:
use std::fs::File;
use std::io;
use std::io::Read;
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("hello.txt");
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e)
};
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e)
}
}
read_username_from_file函數會開啟hello.txt檔案,如果檔案開啟成功,就會去讀檔案儲存的字串資料,如果字串資料讀取成功,就會回傳這筆字串資料。在read_username_from_file函數執行過程中所遭遇到的可恢復錯誤,都會直接以Result列舉包裹並回傳出來。注意程式第10行,我們直接在match關鍵字的arm中使用return關鍵字,看起來似乎有點詭異。
先前雖然提到過,使用大括號{}組成的程式敘述區塊,最後一行的程式敘述如果不加上分號,就會將值回傳出去,且如果只有一行敘述,可以將大括號省略。那如果我們在這種程式敘述區塊內使用return關鍵字呢?舉例來說:
fn main() {
let x = 5;
let y = 6;
let z = {
x + y
};
}
以上程式,再將第5行的x + y改為return x + y,如下:
fn main() {
let x = 5;
let y = 6;
let z = {
return x + y
};
}
程式修改之後,第5行會造成編譯錯誤,因為main函數不能有回傳值!即便把第5行加上分號,改為return x + y;,重新編譯也還是一樣的結果。雖然return關鍵字是寫在這樣一個獨立的程式區塊內,但是它也是算是函數主體程式碼的一部份,因此return關鍵字是可以使用的,但會直接作用在函數上,而不是目前這個程式區塊。其實只要這樣想:if關鍵字所組成的程式區塊可以使用return關鍵字,就能理解了。由此可知,作用在迴圈的break、continue關鍵字也是可以寫在獨立的程式區塊內。
也就是說,Err(e) => return Err(e)這條arm,會讓read_username_from_file函數回傳Err(e),而不是將Err(e)回傳給第二次宣告出來的f變數使用。
因為在實作函數時,「直接將Result列舉的Err實體所包裹的值回傳出去」是很常見的作法,如果一直要用match關鍵字去做型樣匹配實在很麻煩。還好,Rust程式語言提供了一個超方便的語法糖可以解決這個問題,那就是問號?。程式如下:
use std::fs::File;
use std::io;
use std::io::Read;
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("hello.txt");
let mut f = f?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
在Result列舉的實體後加上問號,就可以判斷其是Ok還是Err變體的實體。如果是前者,就會回傳Ok實體所包裹的值;如果是後者,就會直接讓函數回傳Err實體。也由於問號語法會直接讓函數回傳Result列舉的實體,雖然只會有Err變體所產生出來的實體,但是在定義函數的回傳值型別時,還是要把Result列舉的型別給明確地寫上,否則就無法在這個函數內使用問號語法。
總結
Rust程式語言可以使用panic!巨集來處理不可恢復的錯誤,使用Rust列舉來處理可恢復的錯誤。程式開發人員雖然必須依照程式邏輯來自行決定應該要讓程式使用哪種類型的錯誤,但整體來說,簡單的程式,例如範例程式、原型構想,可以直接使用panic!巨集來處理所有錯誤,這樣比較能夠凸顯程式的重點,也可以節省不少程式碼的撰寫時間。此外,測試程式也可以直接使用panic!巨集來處理所有錯誤,測試的最終目的是要讓程式可以毫無錯誤地通過我們預想的每個測試案例,如果在測試過程中就發現錯誤,應該就要停止測試該案例,並同時輸出錯誤訊息,如此一來,程式開發人員就可以去對應的地方修改程式,解決問題。
還有就是我們所使用的函數或是方法雖然會回傳Result列舉的實體,但也並不代表在程式執行階段呼叫它時,就一定有可能會發生錯誤而回傳Err實體。例如將字串定數123使用parse方法轉成數值型別,雖然parse方法還是會回傳Result列舉的實體,但我們知道這樣的程式邏輯是一定不會有錯誤的,此時就可以直接使用Result列舉的實體所提供的expect方法,甚至是直接用unwrap方法,不去自行處理那些不可能會發生的可恢復錯誤。
在下一章節中,我們會學習如何使用泛型和特性,來讓我們的Rust程式變得更加靈活!
下一章:泛型、特性和生命周期。