FFmpeg全名是Fast Forward MPEG(Moving Picture Experts Group),為開源的影音多媒體處理框架,可以進行影音的解碼、編碼、編碼轉換、混合、抽取、串流和濾鏡,無論影音格式是從哪個地方出來的,從過去到現在的影音格式它幾乎都能夠支援。在錄製聲音或是合成聲音的之後,為了避免音量太小聲,或是與其它段的聲音音量差距太大,所以還需要再替聲音做「正規化」(normalization)的動作,而FFmpeg也能夠被用來處理聲音的正規化。
峰值正規化
峰值正規化(Peak Normalization)是以該段聲音中波形振幅最大的位置為參考點,將整段聲音整體放大或縮小,使該段聲音中波形振幅最大的位置移動到指定的準位上。與峰值正規化十分相像的還有有效值正規化(RMS Normalization),它的參考點就不是選在波形振幅最大的位置上,而是以整個波形的音量有效值(或者稱均方根值,Root Mean Square)準位作為參考點,然後同樣將整段聲音的音量整體放大或縮小,使得該段聲音的音量有效值移動到指定的準位上。
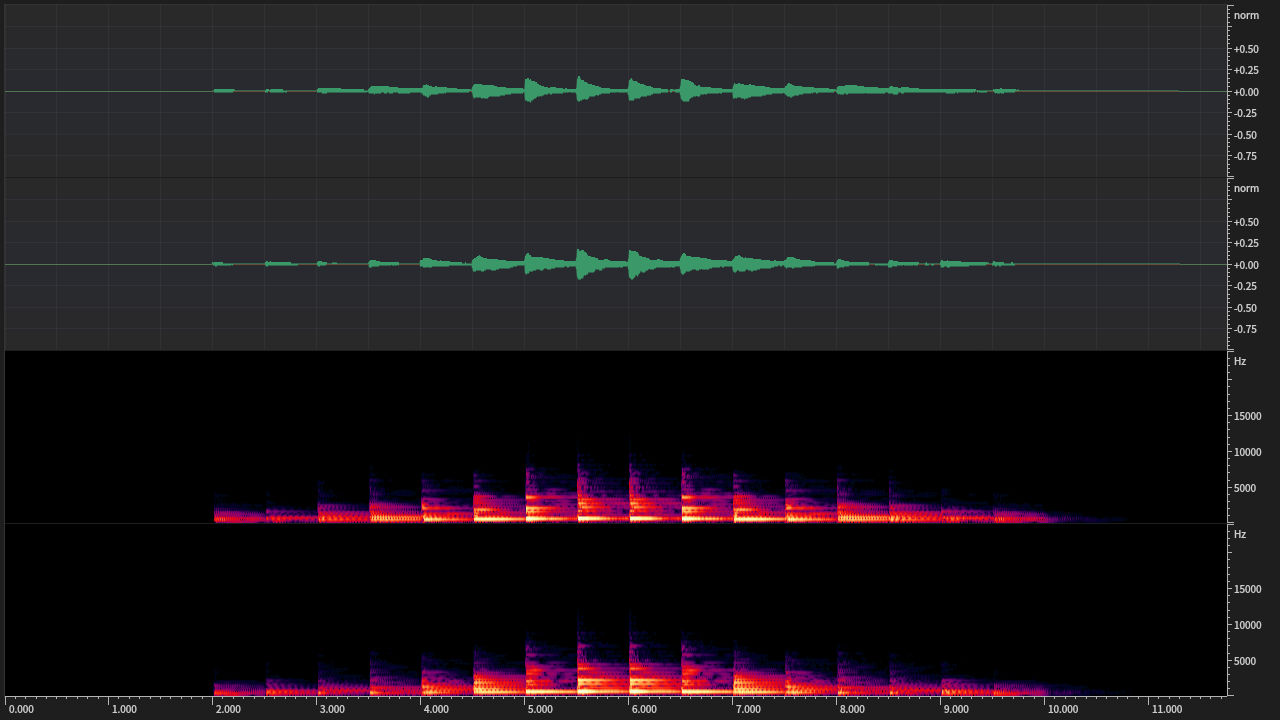
舉例來說,下圖是一段音量偏小的聲音的波形:
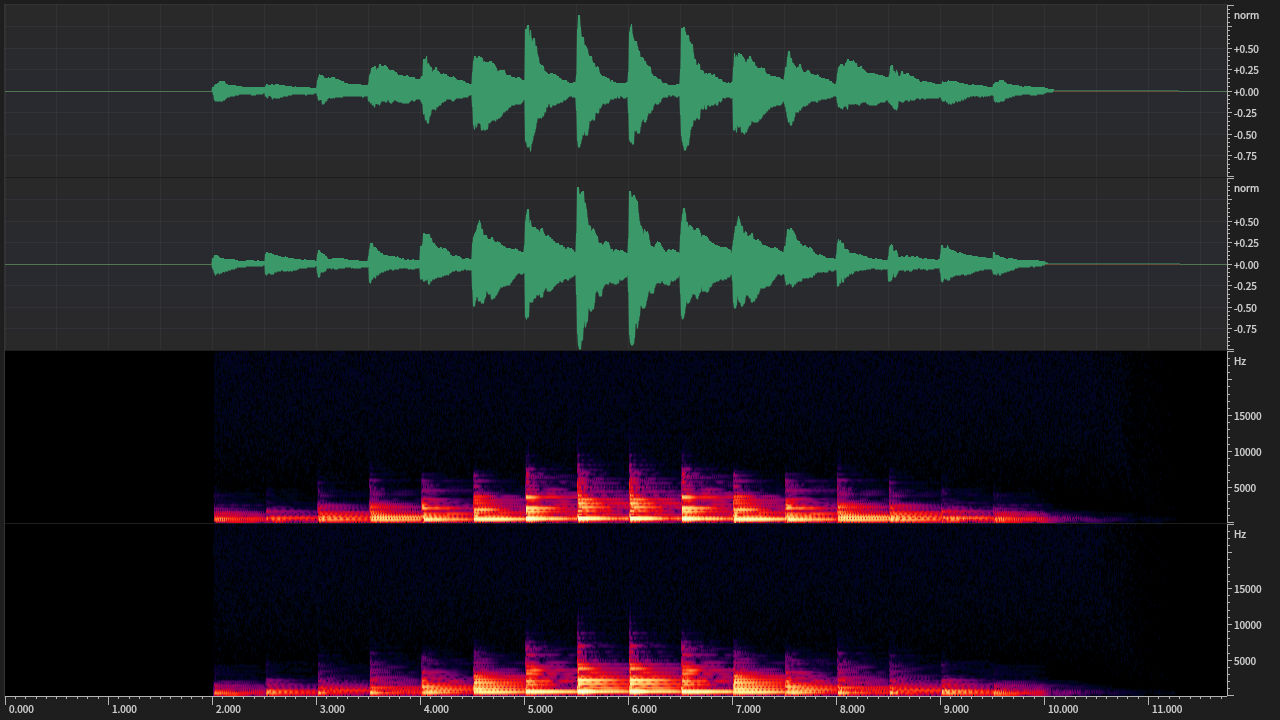
而下圖是這段聲音經過峰值正規化後音量放大的波形:
如果您看波形圖沒什麼感覺的話,可以比較一下這個聲音在峰值正規化前後的差異:
如何?能聽出來峰值正規化後,音量增大了許多嗎?就像是把音樂播放器音量調大了一樣。
在使用峰值正規化的時候,只要我們不把波形振幅最大的位置移動到超出數位可表示的音量最大值,這個波形就不會發生爆音(clip)而失真。但是在使用有效值正規化時,即便我們設定音量有效值在處理後不超過音量最大值,還是有可能會使得原本音量大於有效值的位置在被放大後超過音量最大值而失真。峰值正規化是最簡單實用的正規化方式。
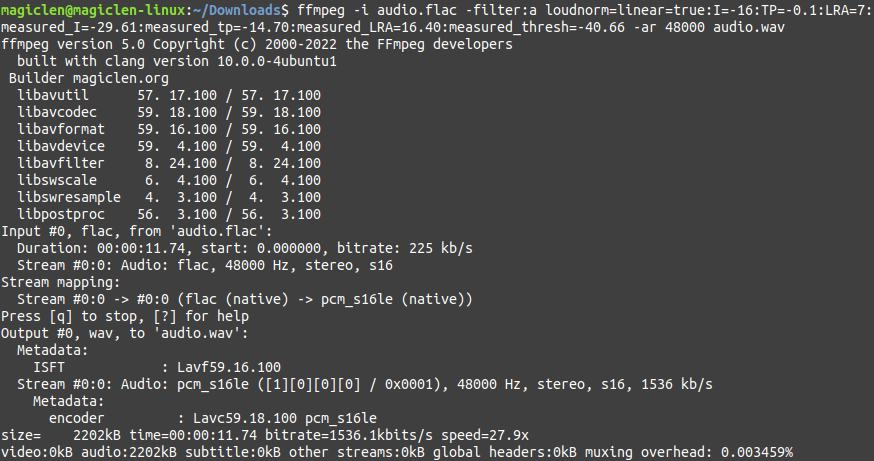
要使用FFmpeg來進行峰值正規化,需要執行二次的處理。第一次要先找出整段聲音的音量最大值,指令如下:
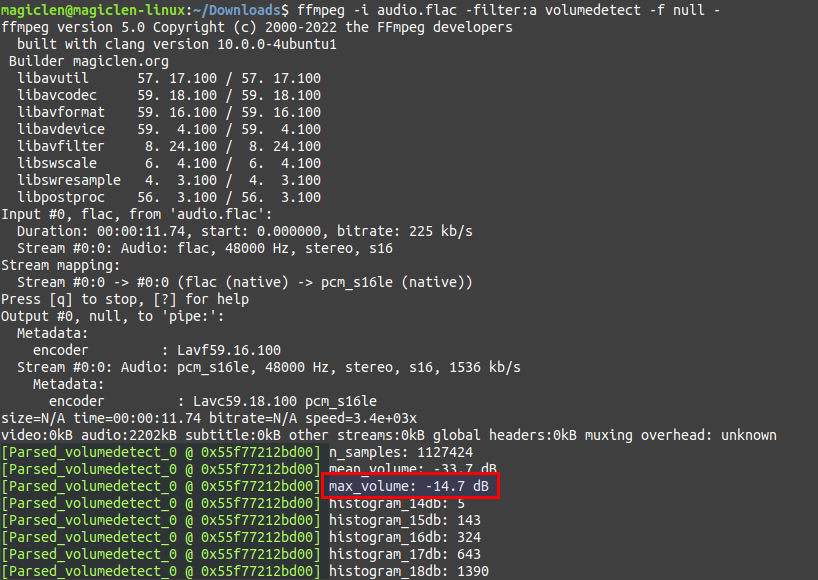
指令執行後,我們需要關注的是max_volume值。如上圖紅框所在的地方,顯示-14.7dB,表示該段聲音中波形振幅最大的位置還要在放大+14.7dB才能夠到達音量最大值。為了避免影音播放器、編碼器本身會將音量放大而造成失真,通常我們會讓聲音在做峰值正規化時,將峰值指定在0 ~ -3dB。在這裡以-0.1dB為例,若要把需要放大+14.7dB才能夠到達音量最大值的聲音放大+14.6dB,指令如下:
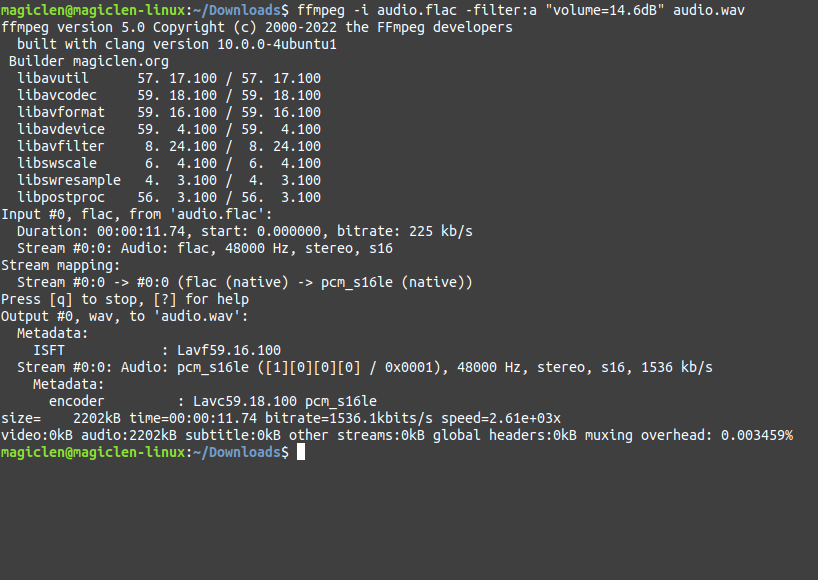
如此便能得到max_volume值在-0.1dB的聲音。
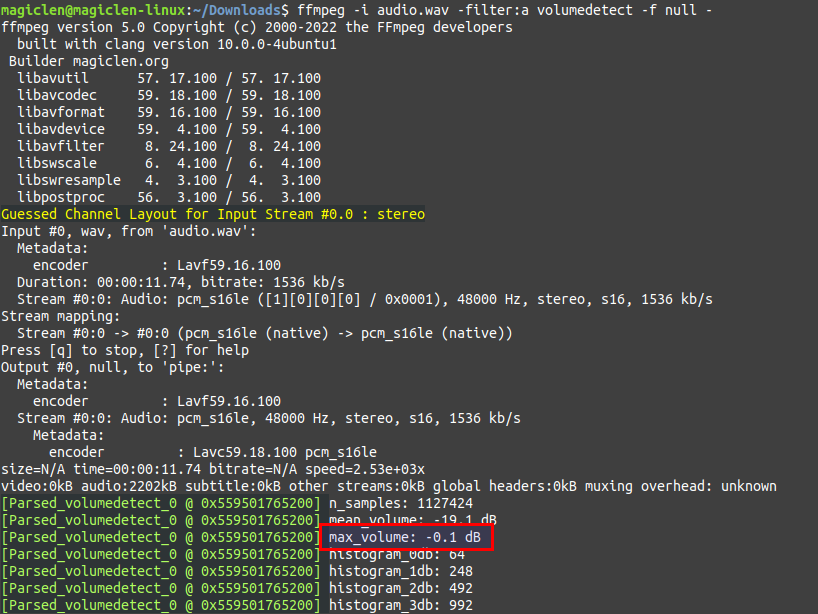
以上的兩行指令在Unix-like環境下也可以縮短成為一行(0 dB),如下:
INPUT_FILE=/path/to/input-audio-file; ffmpeg -i "$INPUT_FILE" -filter:a "volume=$(ffmpeg -i "$INPUT_FILE" -filter:a volumedetect -f null - 2>&1 | grep max_volume | awk -F " " '{print -$(NF-1) - 0.1}')dB" /path/to/output-audio-file
以上指令,0.1表示要讓輸出的聲音之max_volume值為-0.1dB。
響度正規化
響度正規化(Loudness Normalization)是以「人」感知到的音量大小作為參考點(非物理上的聲波振幅),將整段聲音的各部份放大或縮小,使得該段聲音聽起來的響度是在指定的準位上。
為什麼要做這件事情?
起因與廣播電視的節目有關,當觀眾或聽眾切換不同的頻道,或是從一個節目進到下一個節目、從節目進廣告,甚至是在同一個節目之中,如果音量有明顯的變化,他們就需要經常去調節設備播放出來的音量,不太方便也破壞體驗。因此會需要對響度訂一個統一的標準,讓它能在同樣的準位上變化,且變化範圍也要有所限制,不然太大聲就會爆音,太小聲又會聽不到。
歐洲廣播聯盟(EBU, European Broadcasting Union)在ITU-R BS.1770標準的基礎之上,對響度的演算細節作了更明確的定義,定訂出了EBU R.128標準。FFmpeg提供支援EBU R.128的loudnorm濾鏡,但是在使用前還有一些概念需要先提及:
- 響度與聲波振幅並沒有絕對的關係,最大響度不一定會出現在最大振幅的位置。
- LU (Loudness Unit):響度的相對單位。1 LU = 1 dB。
- LUFS (Loudness Unit Full Scale):響度絕對單位。1 LUFS = 1 dBFS。最大響度是
0 LUFS,最大響度的一半就是-3 LUFS。 - I (Integrated Loudness):整體響度。以LUFS為單位。不同類型的聲音會有不同的響度建議值,例如音樂為14 LUFS,廣播為23 LUFS。
- TP (True Peak):真正的峰值。為了避免最大響度出現在數位取樣點之間(inter-sample peak),所以用過取樣(oversampling)的方式來建立響度波形,最大響度的位置即為TP。
- LRA (Loudness Range):響度的變化範圍,最大響度和最小響度的差異(有一定比例的最大聲和最小聲的部份不會被列入分析)。原則上,在愈吵雜的環境下,LRA愈小,體驗會更好。不同類型的音樂或聲音對於響度變化範圍的要求也不同。
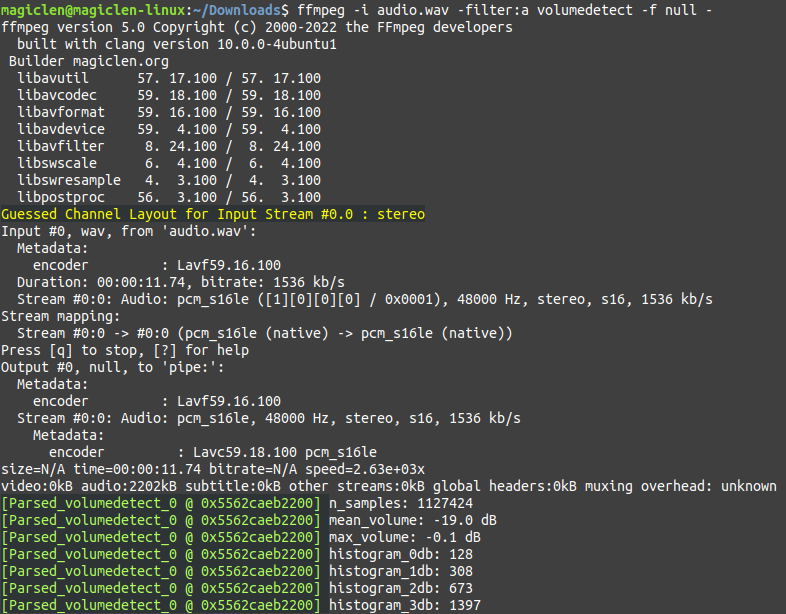
要使用FFmpeg來進行峰值正規化,需要執行二次的處理。第一次要先找出整段聲音的I、TP、LRA等等的數值,指令如下:
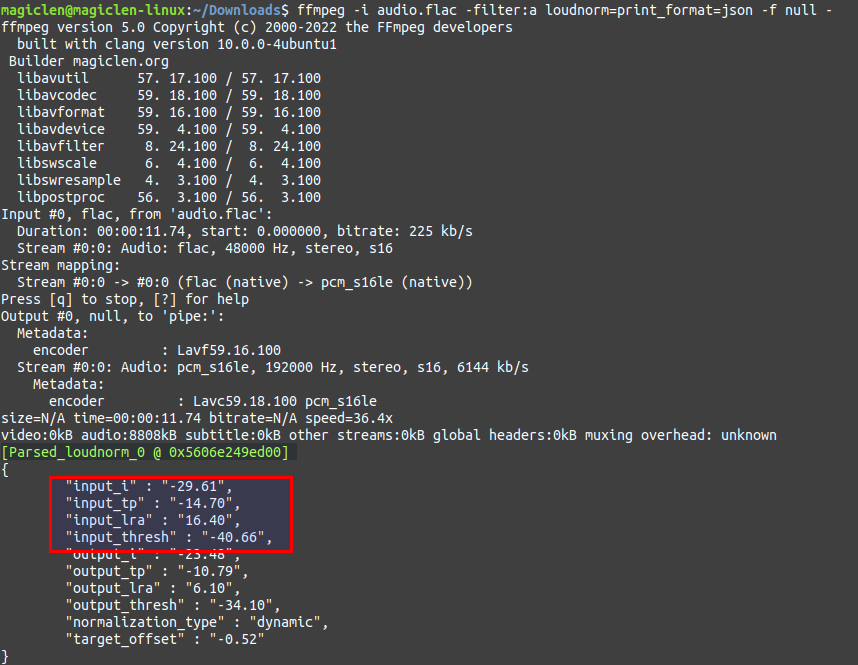
分析結果會以JSON格式文字直接印在標準輸出(stdout)中,我們需要看的欄位有input_i、input_tp、input_lra、input_thresh。thresh值,筆者也不太確定是什麼,或許是響度低於這個值的話就被視為無聲,而不會列入分析吧?
接著執行以下格式的指令,來輸出新的音訊。
如以上的指令格式,請把第一次處理時得到的input_i、input_tp、input_lra、input_thresh數值填進指令中,接著調整I、TP和LRA的數值,再於-ar參數後設定要輸出的取樣頻率(如果不設定的話會是192KHz)。