在這個章節將會介紹許多其它程式語言也都有的基礎概念,包含變數、資料型別、函數、註解以及條件和迴圈的流程控制。
變數
我們其實已經會用變數了,這邊再加強一下觀念。在上一章節中,我們提到了使用let宣告出來的變數是不可變的,如果要讓變數可變,需要加上mut關鍵字。這樣的設計習慣雖然和其它語言差異蠻大,但也是有它的優點在,如果變數預設被宣告出來後就可以一直被改變的話,我們很容易就會不小心改掉某個重要變數的值而導致程式執行結果有誤,通常發生這樣的情況後,會需要不少的時間才能找出問題所在,然而Rust程式語言這樣的設計習慣卻能在撰寫程式碼的階段就已經大大地減少這個情況發生的可能性了。
但所謂的「不可變的變數」,究竟是指「變數本身儲存的值」不會改變,還是「變數儲存的值本身」不會改變呢?
來做一個小實驗,程式如下:
fn main() {
let s1 = String::new();
let mut s2 = String::new();
s1.push_str("s1");
s2.push_str("s2");
println!("{s1}");
println!("{s2}");
s1 = String::from("Hello");
s2 = String::from("Hi");
println!("{s1}");
println!("{s2}");
}
注意程式第5行和第11行,我們分別對沒有使用mut的s1變數的值和s1變數本身所儲存的值進行修改的動作,程式編譯的結果如下:
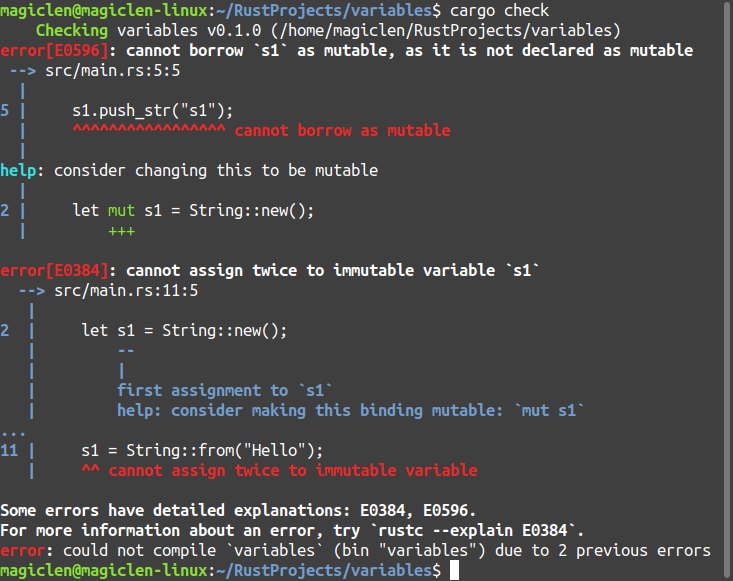
根據上圖,我們可以看到程式第4行和第9行都是無法通過編譯的!也就是說「不可變的變數」,「變數本身儲存的值」不會改變,且「變數儲存的值本身」也不會改變。若將s1變數加上mut關鍵字來宣告,程式即可通過編譯。
「不可變的變數」不就跟常數(constant)是一樣嗎?雖然它們看起來都是值不可以改變的名稱,但還是有一些差異。在Rust程式語言中,提供了const關鍵字來宣告常數,與用let宣告變數不同的是,const不允許加上mut關鍵字來讓常數變成可變的,因為「可變的常數」就根本不是常數了嘛!再來就是const宣告常數時,必須要明確地給出常數的型別,因為常數的值在Rust程式的編譯階段時,就需要確定下來了,換句話說,常數也無法儲存程式執行階段才能得到的資料。常數可以被宣告在任何的scope,包含全域的scope,且名稱習慣都使用大寫字母,並使用底線區隔不同的單字。例如:
const MAX_POINTS: u32 = 100000;
常數存在的目的是要讓程式碼更容易維護,利用常數來表示程式碼之後可能會更動的設定值是很常見的用法。上一章提到的變數「遮蔽」(shadowing),常數並沒有這種特性,如果在同一個程式scope下,宣告了相同名稱的常數,程式就會編譯錯誤。
有關於變數「遮蔽」,舉個一般的例子:
fn main() {
let x = 5;
let x = x + 1;
let x = x * 2;
println!("The value of x is: {x}");
}
以上程式第4行和第6行,由於重複使用x這個名稱宣告變數,因此發生「遮蔽」。由於等號右邊會比左邊先執行,因此第4行等號右邊的x變數為第2行宣告的x變數,所以要進行5 + 1這個運算,並將結果6指派給第4行宣告出來的x變數儲存。同理,第6行等號右邊的x變數為第4行宣告的x變數,所以要進行6 * 2這個運算,並將結果12指派給第6行宣告出來的x變數儲存。所以最後程式會輸出:
變數只需相同名稱即可「遮蔽」,因為其實就是再宣告出一個新的變數來用了,所以就算型別不同也可以。舉例來說:
fn main() {
let spaces = " ";
let spaces = spaces.len();
}
以上程式第4行,由於重複使用spaces這個名稱宣告變數,因此發生「遮蔽」。第2行宣告出來的spaces變數型別為字串(確切來說是&str),第4行宣告出來的spaces變數型別為整數數值(確切來說是usize),兩者型別並不一樣,但程式是可以通過編譯的。
那麼「遮蔽」和mut關鍵字的差別在哪裡呢?除了「遮蔽」實際上會宣告出新的變數之外,它們不都是將相同名稱的變數所儲存的值進行改變嗎?以結果來說是這樣沒錯,但還是有用法上的差異。mut關鍵字並不能改變變數的型別,如以下程式:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}
這個程式將會編譯失敗,因為程式第4行,嘗試將整數型別的值指派給字串型別的spaces變數。
資料型別
Rust是「靜態型別」(Static Typing)的程式語言,在編譯階段就要完全決定好變數的型別,因此可以讓Rust程式在編譯階段就知道要怎麼樣儲存和處理該類型的資料。使用let關鍵字宣告變數的時候,通常可以不用事先指定好該變數的型別,因為編譯器會自動根據第一次指派給變數的值來推論變數的型別。舉例來說:
fn main() {
let a;
let b = 1;
a = 2;
}
以上程式,變數a在宣告時並未指定型別,而且也沒有指派任何值。然而編譯器知道程式第4行會將i32型別的2指派給變數a,因此自動推論變數a的型別是i32。
在某些情況下,由於「泛型」的關係有多種型別的可能,因此需要事先定義好變數的型別。前面的章節製作的猜數字程式,第二次宣告出來的guest變數就是一個需要事先明確定義好型別的例子。
let guess: i32 = guess.trim().parse().expect("Please type a number!");
純量型別(Scalar Types)
只有一個值的型別稱為「純量型別」,Rust程式語言中一共有四種基本的純量型別,分別是整數(integer)、浮點數(floating-point)、布林(boolean)、字元(character),底下將分別介紹這四種型別。
整數
沒有小數位數的數值就是整數,Rust程式語言對於整數數值型別,區分了有號整數(i)和無號整數(u),整數依照表示範圍區分為8位元、16位元、32位元、64位元和128位元。先前我們已經使用過了i32型別,用來表示32位元的有號整數,32位元的有號整數可以表示-231 ~ 231-1的整數數值範圍。如果是要使用8位元的有號整數,型別名稱為i8,依此類推。不同長度的有號整數的數值表示範圍公式如下:
將i32的i改為u,變成u32,可用來表示32位元的無號整數,32位元的無號整數可以表示0 ~ 232-1的整數數值範圍。如果是要使用8位元的無號整數,型別名稱為u8,依此類推。不同長度的無號整數的數值表示範圍公式如下:
此外,有號整數和無號整數分別還有isize和usize這兩種型別能夠使用,它們的長度會跟程式的執行環境有關。如果程式是在32位元的環境下執行(如x86),則isize和usize都會使用32位元;如果程式是在32位元的環境下執行(如x86_64),則isize和usize都會使用64位元。
直接在Rust程式碼中撰寫整數數值的話,會直接當作i32型別來處理,如果預設使用isize的話會造成很多不確定的因素,如果預設使用i64則是會太佔儲存和運算資源。Rust程式語言支援的整數寫法有很多種,除了一般直接寫數字的方式外,還允許加上底線_來分割太多位數的整數。例如:
let x = 12_345;
如同其它大部份程式語言,Rust的整數也支援16進制、8進制、2進制的表示方式。如下:
let h = 0xff;
let o = 0o377;
let b = 0o11111111;
此外,還有一種針對字元值轉換成u8型別的寫法。如下:
fn main() {
let c0 = b'0';
let cA = b'A';
println!("0 = {c0}, A = {cA}");
}
執行結果為:
有號整數的型別有i8、i16、i32、i64、i128和isize。無號整數的型別有u8、u16、u32、u64、u128和usize。請參考以下程式:
fn main() {
let a = 1i8; // i8
let a: i8 = 1; // i8
let a = 1 as i8; // i8
let a = 1i16; // i16
let a: i16 = 1; // i16
let a = 1 as i16; // i16
let a = 1; // i32
// let a = 2147483648; // i32
let a = 2147483648i64; // i64
let a: i64 = 2147483648; // i64
let a = 2147483648 as i64; // i64
// let a = 9223372036854775808; // i32
let a = 9223372036854775808i128; // i128
let a: i128 = 9223372036854775808; // i128
let a = 9223372036854775808 as i128; // i128
let a = 1u8; // u8
let a: u8 = 1; // u8
let a = 1 as u8; // u8
let a = b'1'; // u8
let a = 1u16; // u16
let a: u16 = 1; // u16
let a = 1 as u16; // u16
let a = 1u32; // u32
let a: u32 = 1; // u32
let a = 1 as u32; // u32
let a = 1u64; // u64
let a: u64 = 1; // u64
let a = 1 as u64; // u64
let a = 1u128; // u128
let a: u128 = 1; // u128
let a = 1 as u128; // u128
}
程式第8行,直接在程式碼寫的整數數值會預設使用i32型別。程式第9行,2147483648為231,已經超過i32的數值表示範圍,但Rust並不會自動使用i64來儲存,如果這行沒有被註解掉的話,編譯器會知道寫在程式碼的整數數值超出i32型別的表示範圍(溢位),編譯時就會出現警告訊息。但是程式第10行,直接在在程式碼中的整數數值後面接上i64,這個數值就會被轉型為i64,解決了溢位問題。程式第12行,使用as關鍵字也可以解決溢位問題;程式第13行,9223372036854775808i128為263,已經超過i32和i64的數值表示範圍,但Rust並不會自動使用i128來儲存,如果這行沒有被註解掉的話,編譯器會知道寫在程式碼的整數數值超出i32型別的表示範圍(溢位),編譯時就會出現警告訊息。但是程式第14行,直接在在程式碼中的整數數值後面接上i128,這個數值就會被轉型為i128,解決了溢位問題。程式第16行,使用as關鍵字也可以解決溢位問題。
再整理一下,自行定義寫在程式碼的整數數值型別的方式有三種:第一種是在整數數值之後直接接上整數型別名稱(程式第2、5、10、14、18、22、25、28、31行),第二種是透過宣告變數時定義變數的型別(程式第3、6、11、15、19、23、26、29、32行),第三種是使用as關鍵字來轉型(程式第4、7、12、16、20、24、27、30、33行)。這裡要注意一下,浮點數數值無法直接接上整數型別名稱來轉成整數型別。
浮點數
有小數位數的數值就是浮點數,Rust程式語言對於浮點數數值型別,依照精準度區,將長度分為32位元的f32(單精準浮點數)和64位元的f64(雙精準浮點數)。直接在Rust程式碼中撰寫浮點數數值的話,會直接當作f64型別來處理,因為f64能夠提供比f32還要更精確的數值,且運算速度在現代的CPU上是差不多的。
浮點數的型別有f32、f64。請參考以下程式:
fn main() {
let a = 1.0f32; // f32
let a = 1f32; // f32
let a: f32 = 1.0; // f32
let a = 1.0 as f32; // f32
let a = 1 as f32; // f32
let a = 1f64;
let a = 1.0; // f64
let a = 1 as f64; // f64
}
程式第9行,直接在程式碼寫的浮點數數值會預設使用f64型別。
自行定義寫在程式碼的浮點數數值型別的方式有三種:第一種是在整數數值或浮點數數值之後直接接上浮點數型別名稱(程式第2、3、8行),第二種是透過宣告變數時定義變數的型別(程式第4行),第三種是使用as關鍵字來轉型(程式第5、6、10行)。
浮點數和整數型別之間的轉換一定要透過as關鍵字。以下的寫法都會編譯失敗:
let a: i32 = 1.0;
let a: f64 = 1;
必須改用as關鍵字才可以編譯成功:
let a = 1.0 as i32;
let a = 1 as f64;
如果是整數(或浮點數)變數要轉換成其它整數(或浮點數)型別,方式和直接寫在程式碼的數值一樣:透過宣告變數時定義變數的型別,或是使用as關鍵字來轉型,而浮點數和整數型別之間的轉換也是一定要透過as關鍵字。
布林
和其它大多數的程式語言一樣,Rust的布林型別也只有true和false兩種值。布林的型別名稱為bool。
字元
除了數值類型的型別之外,Rust程式語言也支援char型別,可以用來處理字元。直接寫在程式碼的字元必須使用單引號'包起來,例如:
let c = 'C';
char型別可以表示「Unicode Scalar」編碼的值,也就是說,除了ASCII字元外,還可以表示中文、日文、韓文(CJK)的文字,也能表示表情符號。
複合型別(Compound Types)
複合型別可以將不同型別的值組合成一個型別。Rust程式語言提供了兩種基本的複合型別,分別是「元組(tuple)」和「陣列(array)」。
元組
元組是一個將不同型別的值組合成一種型別的常用方式。在Rust程式語言中,可以利用逗號,在小括號()內分隔不同型別的值,就能將它們組合成元組。例如:
let t = (500, 6.4, 1, 'A'); // (i32, f64, i32, char)
以上程式,t變數的型別就是一種元組型別,可以用(i32, f64, i32, char)來表示。換句話說,如果要在宣告變數時明確定義變數的元組型別,可以將程式寫成:
let t: (i32, f64, i32, char) = (500, 6.4, 1, 'A');
由於元組並未定義每個值所屬欄位的名稱,但因其有順序性,因此可以利用以下程式的語法,快速地將元組中的值指派給不同變數。
let t = (500, 6.4, 1, 'A');
let (a, b, c, d) = t; // a: i32, b: f64, c: i32, d: char
這裡要注意的是,只有在使用let關鍵字宣告變數時,才可以直接將元組拆開。如果程式是寫成以下這樣的話,會編譯失敗:
let t = (500, 6.4, 1, 'A');
let a;
let b;
let c;
let d;
(a, b, c, d) = t;
以上程式需要改寫成以下的樣子,才能通過編譯:
let t = (500, 6.4, 1, 'A');
let a;
let b;
let c;
let d;
a = t.0;
b = t.1;
c = t.2;
d = t.3;
元組的順序是從索引0開始計算,可以利用.符號使用索引值指定要存取的元組欄位。元組的索引值在程式編譯階段就要決定好,無法使用變數或是常數代替。
let mut t = (500, 6.4, 1, 'A');
t.0 = t.2;
以上程式,將元組t索引2的1存到索引0的位置,取代掉原本索引0的500。
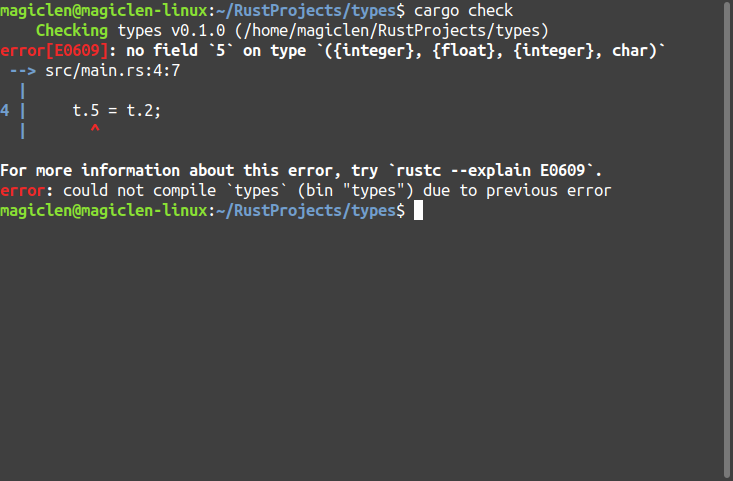
如果嘗試使用超出元組範圍的索引值,在程式會編譯失敗。例如:
fn main() {
let mut t = (500, 6.4, 1, 'A');
t.5 = t.2;
}
編譯結果如下圖:
陣列
陣列的概念像是元組的簡化版,元組可以儲存多個不同型態的值,而陣列只能儲存多個相同型態的值(在陣列中稱為元素值(element))。Rust程式語言的陣列為固定長度,既不能增長也不能縮小,且長度在編譯階段時就要決定。利用逗號,在中括號[]內分隔相同型別的值,就能將它們組合成「陣列」。例如:
let a = [2, 4, 6, 8, 10]; // [i32; 5]
以上程式,a變數的型別就是一種陣列型別,且長度為5,可以用[i32; 5]來表示。換句話說,如果要在宣告變數時明確定義變數的陣列型別和陣列長度,可以將程式寫成:
let a: [i32; 5] = [2, 4, 6, 8, 10];
與元組相同,由於陣列並未定義每個元素所屬欄位的名稱,但因其有順序性,因此可以利用以下程式的語法,快速地將陣列中的元素指派給不同變數。
fn main() {
let a = [2, 4, 6, 8, 10];
let [v, w, x, y, z] = a;
}
同樣地,只有在使用let關鍵字宣告變數時,才可以直接將陣列拆開。如果程式是寫成以下這樣的話,會編譯失敗:
let a = [2, 4, 6, 8, 10];
let v;
let w;
let x;
let y;
let z;
[v, w, x, y, z] = a;
以上程式需要改寫成以下的樣子,才能通過編譯:
let a = [2, 4, 6, 8, 10];
let v;
let w;
let x;
let y;
let z;
v = a[0];
w = a[1];
x = a[2];
y = a[3];
z = a[4];
陣列的順序是從索引0開始計算,可以利用中括號[]使用索引值指定要存取的陣列欄位。陣列的索引值可以在程式執行階段才決定。
let mut a = [1, 2, 3, 4];
a[0] = a[2];
以上程式,將陣列a索引2的3存到索引0的位置,取代掉原本索引0的1。
此外,也可以利用陣列所提供的get方法來取得元素值。
let mut a = [1, 2, 3, 4];
let x = a.get(0);
使用get方法回傳的陣列元素值會被Option列舉包裹起來。Option列舉在之後的章節會作介紹。
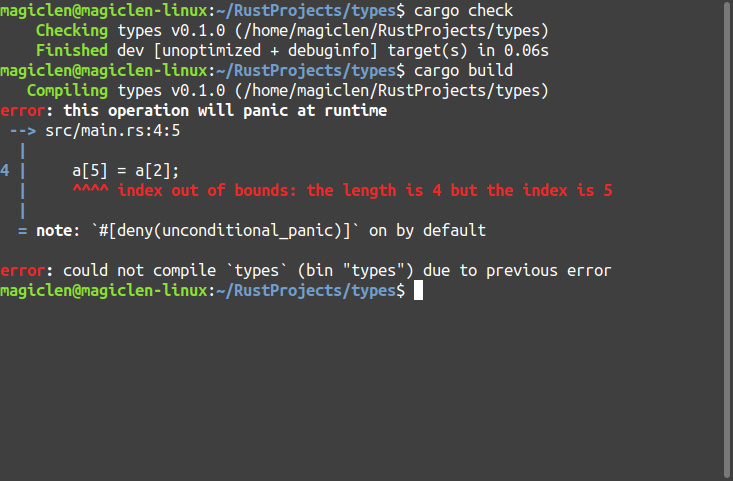
利用中括號[]使用超出陣列長度範圍的索引值嘗試存取元素值,程式雖然可以通過cargo check,但在預設情況下無法通過cargo build。因為這是屬於Lint方面的問題,這類問題硬是要進行編譯是不會有錯誤的,甚至可被編譯器給自動忽略或修正掉。如果是不能被編譯器修正,在程式執行階段才會出現錯誤但又顯而易見的問題,這樣的問題就會交給Lint來檢查,在編譯階段阻止問題的發生。
例如:
fn main() {
let mut a = [1, 2, 3, 4];
a[5] = a[2];
}
編譯結果如下圖:
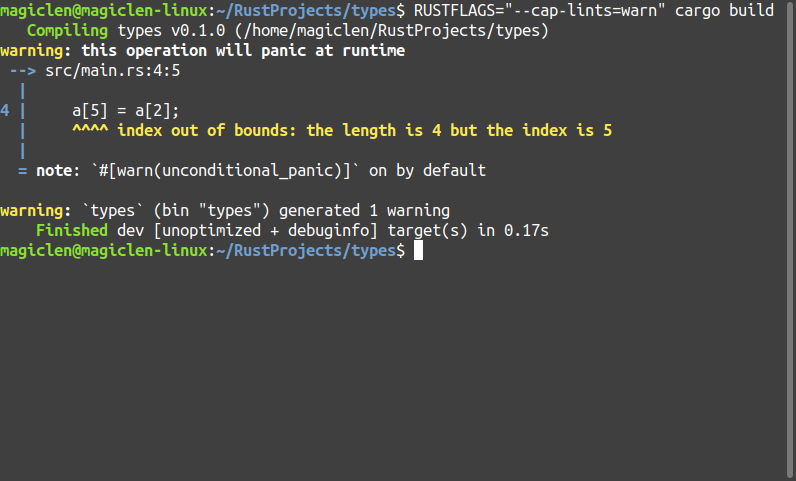
當然我們也可以強制讓Rust編譯器忽略Lint檢查出來的錯誤,可以加上--cap-lints=warn參數給Rust編譯器,使Lint錯誤變成警告。我們可以利用RUSTFLAGS環境變數將參數帶給Rust編譯器。所以原本的cargo build指令就要改寫為:
RUSTFLAGS="--cap-lints=warn" cargo build
此處只是為了演示程式執行階段才出現的錯誤,在實際使用上我們最好不要用這樣的方式來使程式通過編譯。因為這樣的程式雖然通過編譯,但在執行階段還是會出問題的。
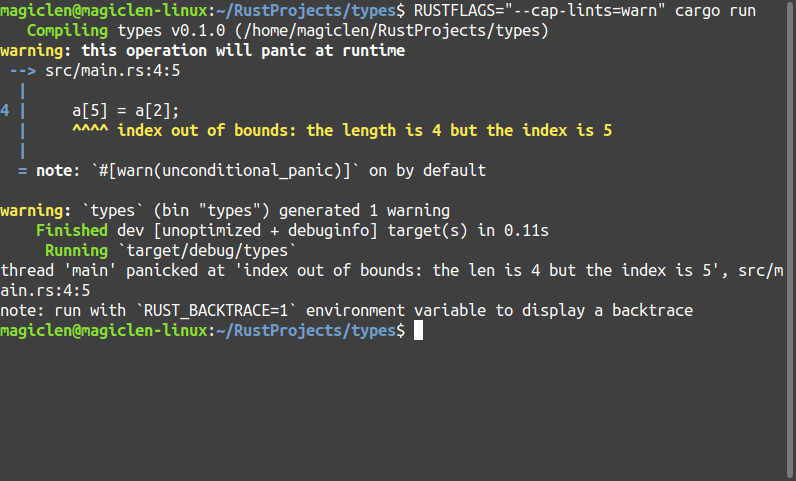
不過,從上圖可以發現,當索引值超出陣列範圍時,程式會在執行階段發生panic。這其實也表示,Rust程式語言在程式執行階段還是會去維護陣列的長度範圍,雖然會消耗一些運算資源,但這樣的作法會比如C、C++這樣的底層語言,它們在當索引值超出陣列範圍時還能繼續操作記憶體,來得安全許多。
如果要建立出一個固定長度的陣列,但陣列元素目前還無法確定的話,也可以直接將陣列寫成:
[每個欄位的初始元素值; 陣列長度]
舉例來說:
fn main() {
let mut a = [0; 4];
a[0] = 1;
a[1] = 2;
a[2] = 3;
a[3] = 4;
}
函數
程式語言最重要的觀念就是函數啦!我們先前已經有使用過fn關鍵字來定義main函數,並且也知道main函數為特別的函數,被用來作為程式一開始執行的函數。若要建立出新的函數,同樣使用fn關鍵字,格式如下:
fn 函數名稱(參數名稱和型別) {
主體的程式敘述
}
例如:
fn another_function(name: &str) {
println!("Hi, {name}.");
}
Rust程式語言並未限制定義函數的順序。舉例來說,以下兩個程式都是可以編譯的:
fn main() {
another_function("world");
}
fn another_function(name: &str) {
println!("Hi, {name}.");
}
fn another_function(name: &str) {
println!("Hi, {name}.");
}
fn main() {
another_function("world");
}
函數的名稱和參數的型別可以組合成函數的「簽名」,「簽名」相同的函數視為相同的函數。以上面的程式來說,在main方法中呼叫了another_function("world"),由於寫在程式碼中的字串的型別為&str,因此編譯器知道呼叫的函數簽名為another_function(&str),所以會執行到我們定義的another_function(name: &str)函數,最後印出Hi, world.。
定義函數時使用的大括號{}包裹住的區塊為函數的主體,該區塊可由一行或多行敘述組成,且最後一行的敘述如果不加分號,表示會回傳該敘述的值。事實上,這整個主體區塊也可以看作是程式敘述的表達式(expression),且不限於使用在fn關鍵字。舉例來說:
fn main() {
let x = {
let y = 10;
let z = 4;
println!("y = {y}, z = {z}");
y + z
};
println!("x = {x}");
}
以上程式第2行到第9行,我們也使用了大括號{}定義了一個新的程式區塊。在這個區塊中,會先印出y = 10, z = 4,然後計算並回傳變數y和變數z的結果。而這個回傳的結果會指派給main函數的x變數,最後再印出x = 14。
如果要定義一個有回傳值的函數,同樣是使用fn關鍵字,只不過需要多加上回傳值的型態。如下:
fn 函數名稱(參數名稱和型別) -> 回傳值的型態{
主體的程式敘述
}
我們在函數的簽名和主體之間,多加了->符號來定義函數回傳值的型態。利用這樣的語法,來將上面的x=y+z程式改寫看看:
fn main() {
let x = x(10, 4);
println!("x = {x}");
// println!("x = {}", x(10, 4));
}
fn x(y: i32, z: i32) -> i32 {
println!("y = {y}, z = {z}");
y + z
}
以上程式第2行,將x函數的回傳值指派給宣告出來的變數x。雖然變數和函數的用法不同,但如果都定義成相同名稱的話,也是會無法一起使用。第5行如果解除註解,程式就會編譯失敗。而第2行因等號右邊的程式會先執行的關係,所以呼叫x函數時還沒有將x變數宣告出來,因此可以編譯成功。
常數函數
函數也可以使用const關鍵字來修飾,變成常數函數。常數函數在編譯階段就會被執行,因此無法在參數或是主體中去使用在執行階段才能夠確定的東西。
建議儘量使用常數函數來讓程式在編譯階段就用編譯器把能夠先完成的工作完成!
以下是一個常數函數例子:
fn main() {
println!("x = {}", x(10, 4));
}
const fn x(y: i32, z: i32) -> i32 {
y + z
}
編譯器會去執行常數函數,將以上程式轉成:
fn main() {
println!("x = {}", 14);
}
另外,常數函數也可以在常數上下文(const context)中被呼叫。例如:
const A: i32 = 10 + (x(10, 4) * 4);
// const B: i32 = 10 + (xx(10, 4) * 4); // compilation error
const fn x(y: i32, z: i32) -> i32 {
y + z
}
fn xx(y: i32, z: i32) -> i32 {
y + z
}
以上程式,x是常數函數,可以被直接用於賦值給常數的表達式;而xx不是常數函數,所以它不能被這樣用。
註解
Rust程式語言的單行註解都是由//開頭,直到該行結束。例如:
// So we're doing something complicated here, long enough that we need
// multiple lines of comments to do it! Whew! Hopefully, this comment will
// explain what's going on.
多行註解則是由/*開頭,直到*/結束。例如:
/*
So we're doing something complicated here, long enough that we need
multiple lines of comments to do it! Whew! Hopefully, this comment will
explain what's going on.
*/
在程式碼中加入適當的註解可以讓程式變得更容易理解。
流程控制
大部分的程式語言可以藉由判斷條件來決定要執行哪些程式,以及重複執行哪些程式。
if條件表達式
Rust程式語言提供了if關鍵字和else關鍵字,可以很方便地實作出帶有條件判斷功能的表達式。用法如下:
if 布林值 {
布林值為true時執行的程式敘述區塊
} else {
布林值為false時執行的程式敘述區塊
}
else關鍵字以及其之後的程式敘述區塊可以省略不寫。
舉例來說:
fn main() {
let number = 3;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}
程式執行結果:
若將number變數的值改為7。
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}
程式執行結果:
如果需要進行多個條件的判斷,可以使用else if關鍵字。用法如下:
if 布林值1 {
布林值1為true時執行的程式敘述區塊
} else if 布林值2 {
布林值2為true時執行的程式敘述區塊
} else if 布林值3 {
布林值3為true時執行的程式敘述區塊
} else if 布林值n {
布林值n為true時執行的程式敘述區塊
} else {
以上布林值(布林值1、布林值2、布林值3、...、布林值n)均為false時執行的程式敘述區塊
}
else關鍵字以及其之後的程式敘述區塊可以省略不寫。
舉例來說:
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}
程式執行結果:
由於if關鍵字實作出來的程式碼結構,可整體看作是一個表達式,可以利用大括號{}程式敘述區塊內,最後一行程式敘述不加分號的語法直接回傳數值。
舉例來說:
fn main() {
let condition = true;
let number = if condition {
5
} else {
6
};
println!("The value of number is: {number}");
}
程式執行結果:
因為在不管什麼條件下都一定要回傳數值,因此這樣的if結構用法必須要有else關鍵字,並且回傳值的型態都要一致,否則會編譯失敗。
迴圈
迴圈可以讓相同的程式自動執行一次以上,Rust程式語言提供了loop、while、for關鍵字來建立用途不同的迴圈。
loop迴圈
loop關鍵字所建立的迴圈,必須在迴圈的程式區塊內明確使用break敘述來脫離迴圈,否則會一直重複執行下去。用法如下:
loop {
要重複執行的程式敘述區塊
}
舉例來說:
fn main() {
loop {
println!("again!");
}
}
以上程式執行之後,程式將會不停地將again!文字一行一行地印在螢幕上。在CLI(命令列介面)模式下,可以使用快速鍵Ctrl + c來中斷程式的執行。
如果將程式改寫成:
fn main() {
loop {
println!("again!");
break;
}
}
我們在程式第4行加入了break敘述,因此程式在執行之後,只會印出一行again!文字,然後就跳出迴圈,結束執行了。
如果只是要跳過這次迴圈的執行,直接到下一次的話,可以使用continue敘述。舉例來說:
fn main() {
let mut number = 0;
loop {
number += 1;
if number % 2 == 0 {
println!("{number}");
} else {
continue;
}
println!("check if number == 10");
if number == 10 {
break;
}
}
}
以上程式中的第5行,number += 1其實就是number = number + 1。
執行結果為:
check if number == 10
4
check if number == 10
6
check if number == 10
8
check if number == 10
10
check if number == 10
while迴圈
while關鍵字所建立的迴圈可以藉由判斷布林值來決定要不要脫離迴圈。用法如下:
while 布林值 {
布林值為true時要重複執行的程式敘述區塊
}
舉例來說:
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number = number - 1;
}
println!("LIFTOFF!!!");
}
以上程式,當number變數不等於0的時候就會一直執行while迴圈內的程式敘述。執行結果如下:
2!
1!
LIFTOFF!!!
while迴圈內的程式敘述區塊也可以使用break和continue敘述。
for迴圈
先繼續剛才介紹的while迴圈,我們可以利用while迴圈來走訪一個陣列。例如:
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("the value is: {}", a[index]);
index += 1;
}
}
程式執行結果:
the value is: 20
the value is: 30
the value is: 40
the value is: 50
雖然程式執行結果是正確的,但這樣的實作方式經常會不小心因為陣列長度沒有設好或算好,超出範圍而導致程式發生panic。而且就算是使用正確長度,這樣的寫法執行效率也不是很好,原因我們在先前有提到,那就是Rust會去檢查陣列的索引值有沒有超出範圍再去存取。為了增加安全性和增進效能,可以使用for關鍵字實作的迴圈來走訪陣列,用法如下:
for 變數名稱 in 陣列.iter() {
要重複執行的程式敘述區塊
}
iter方法是陣列型別內建的方法,會回傳一個Iter結構實體,作為迭代器(Iterator)。
改寫剛才的while迴圈:
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a.iter() {
println!("the value is: {element}");
}
}
另外也可以將陣列參考直接作為迭代器使用。如下:
fn main() {
let a = [10, 20, 30, 40, 50];
for element in &a {
println!("the value is: {element}");
}
}
除了使用陣列本身提供的迭代器之外,for迴圈也可以搭配範圍(range)語法所產生的某數值範圍的迭代器來使用。用法如下:
for 變數名稱 in 數值範圍最小值..數值範圍最大值+1 {
要重複執行的程式敘述區塊
}
舉例來說:
fn main() {
for number in 1..4 {
println!("{number}!");
}
println!("LIFTOFF!!!");
}
程式執行結果:
2!
3!
LIFTOFF!!!
這裡要注意到範圍語法的數值範圍最大值必須要加一,才會真正走訪到數值範圍的最大值。1..4語法表示的範圍為「1~3」;2..6語法表示的範圍為「2~5」。如果要剛好讓範圍語法能夠走訪到數值範圍最大值,而不必特別加一的話,可以加上等於=字元。用法如下:
for 變數名稱 in 數值範圍最小值..=數值範圍最大值 {
要重複執行的程式敘述區塊
}
1..=4語法表示的範圍為「1~4」;2..=6語法表示的範圍為「2~6」。
另外,迭代器也可以對相同資料提供許多不同的走訪方法,例如rev方法可以顛倒走訪順序。如下:
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("LIFTOFF!!!");
}
程式執行結果:
2!
1!
LIFTOFF!!!
迭代器的enumerate方法可以在走訪資料的同時,去計算目前是第幾次迭代。如下:
fn main() {
for (index, number) in (1..4).enumerate() {
println!("{index}: {number}!");
}
println!("LIFTOFF!!!");
}
程式執行結果:
1: 2!
2: 3!
LIFTOFF!!!
總結
在這個章節中,我們學會了Rust程式語言的變數、資料型別、函數、註解以及條件和迴圈的流程控制。在下一章節中,我們將會學習Rust程式語言跟其它大部份程式語言不一樣概念:擁有權(ownership)。
下一章:瞭解擁有權(Ownership)。